You mention a "time suffix" in the comments of the file.
I was referring to the suffix in the name of the actual .mat file (the file path).
Ok, I found the cause of the splitting. When the input files were generated, some had a suffix _02 added by Brainstorm to the comment, and some did not. This happened non-homogeneously across subjects because some subjects already had an average computed with the exact same number of trials and therefore the same name (with the number of files between brackets), whereas the others also already had an average computed but with a different number of trials.
I apologize I had not noticed this earlier. I must have been very tired when I checked earlier because this now looks blindingly obvious to me. As you can see in the screenshot, I added the tag ‘EqualN’ to these files after they were generated, this is how I select them as input to the grand average process. Obviously, the problem did not occur when I prototyped the analysis because I prototyped it when computing the grand average of the initial subject-level averages (the ones that do not have the tag ‘EqualN’).
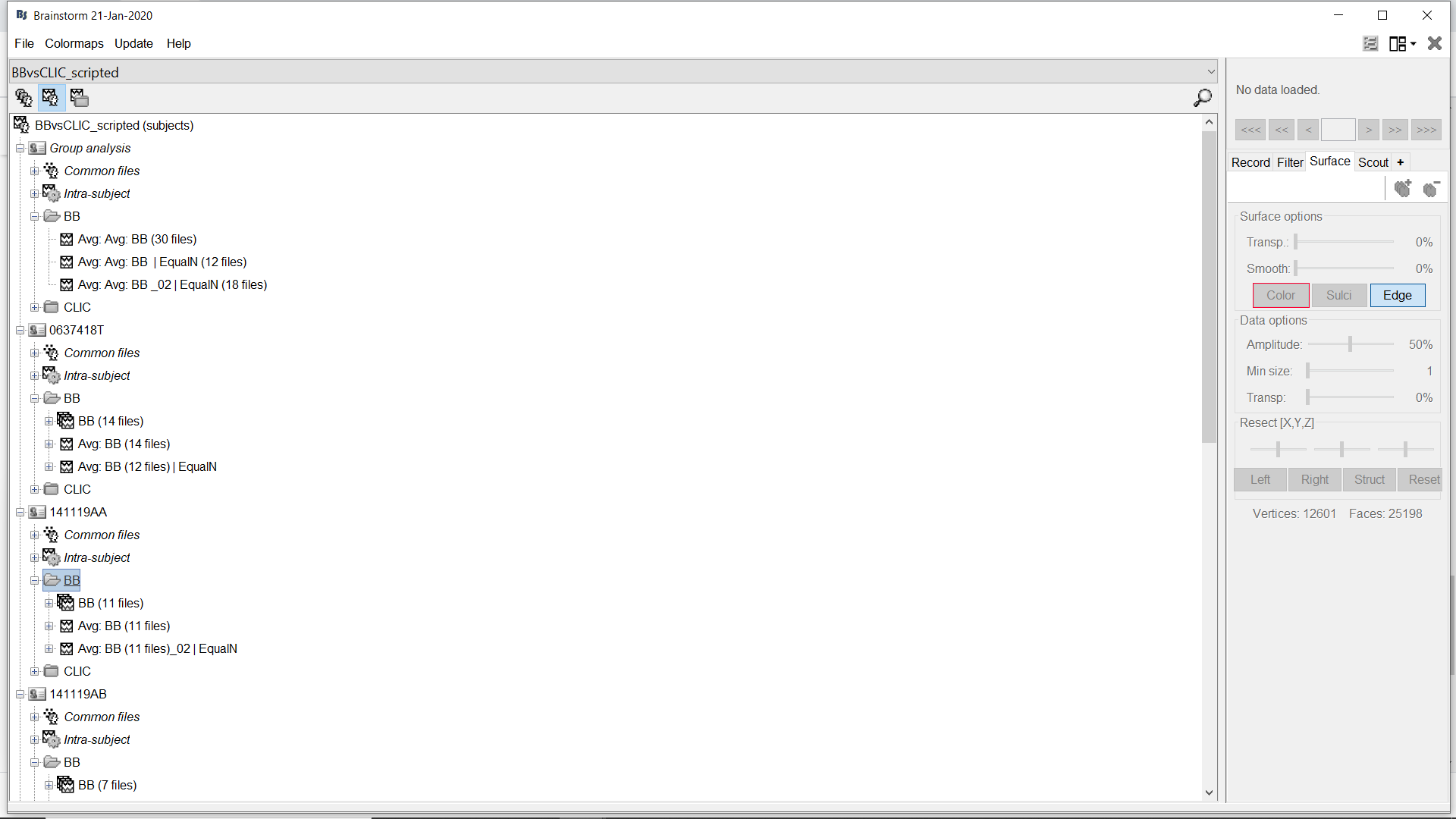
So I’m not sure this is a case that the parser should generally identify. The parser is not sensitive to the number of files indicated between brackets in the name, which is a good thing, but I guess it makes sense that it can discriminate between files that hold a _02, or _0n suffix, or none.