Hello!
I've encountered a strange error as I was getting multiple TF analysis (Morlet wavelet) from source-space data.
Essentially, out of 897 source files, only 3 were processed correctly. All resulted in a file, but some are faulty. When I entered the next step of my pipeline, z-scoring all TF files, I received a strange report concerning the 894 files improperly processed.
This got me to investigate these error-causing TF files. Turns out, they can't be opened.
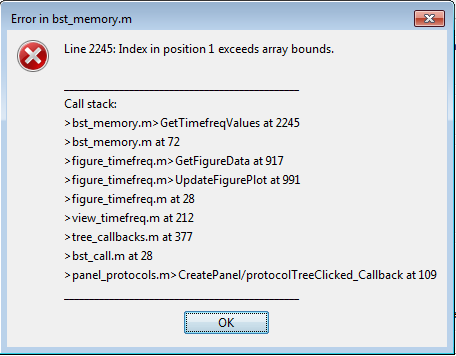
I loaded them in Brainstorm to see what they looked like.
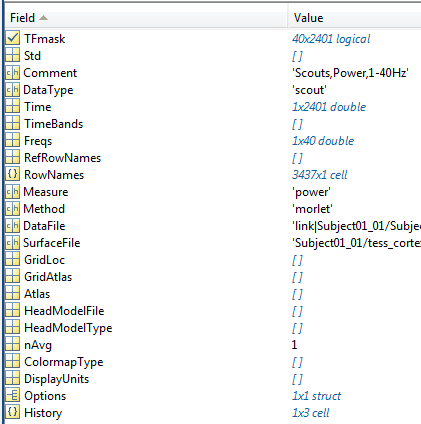
There doesn't seem to be a TF variable in that structure, the variable that usually stores the data.
After that, I ran the TF analysis again on a single problematic source file. The result was a normal TF file that can be opened, read and z-score. The issue then seems to come from the batch processing. It took 24h to my computer to compute all those, so I was wondering if you had a suggestion of a fix before I tried it again.
Please let me know if you have any idea!
No, unfortunately I have no idea what could be the problem, we've never had errors reported where only a part of the file was saved. It could be that the process crashed while updating the structure during the Z-score process, but in my experience this results most of the time in unreadable .mat files that can't be recovered.
It's unlikely to be a memory error, since the files do not seem to be too big...
Is there any part of your processing pipeline that uses close to 100% of the physical memory of your computer? (try running it on a single file with a resource monitor opened)
If there is any software bug in the way the file structures are handled, you should be able to reproduce this with bug with a much smaller number of files. Try first with 10 files instead of rerunning all the 900 files at once.
If you can't reproduce this error, we won't be able to help you much.
If you can reproduce it, please share more details about the full pipeline, and try to identify where is the critical point.
Also adapt your processing pipeline so that the files are never overwritten (so that you would still have the TF results even if the Z-score process fails), it will be easier to debug.
