I'm currently modifying the process that I wrote a few months ago so that the process returns not a single file but several files. That is, if I input 100 epochs I want my script to process the 100 epochs according to the calculation specified and return 100 epochs. I thought this would only require a simple matter of deleting some lines in my script but it looks like this could be more complicated than I first thought.
Right now the script that I wrote with the help of Francois and Raymundo takes in X number of epochs, processes them all at once and returns a single averaged output.
I would like to know where I need to change my file so that the process returns X number of epoch outputs that is the same number of X number of epoch inputs.
The process that I wrote is inspired from the example custom processing.
For Brainstorm to understand that you want to return multiple files, you only need to have the list of all the file paths returned in the cell-array OutputFiles.
You basically need to move all the lines that create a new file (bst_process('GetNewFilename'), save, db_add_data) inside the for loop. Don't forget to increment the index: use OutputFiles{i} instead of OutputFiles{1}.
Thanks for that input Francois.
I took your advice and modified the code as follows.
I included all the lines that are involved in the processing and then outputting/saving the files into the "for" loop so that it returns X number of outputs based on the X number of inputs.
It works well but there are two issues currently.
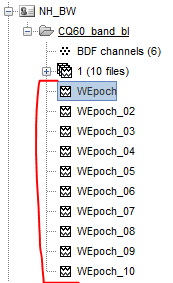
Firstly the process returns my epochs into files as shown rather than the Brainstorm's way of including all the epochs into the "+" files group. How do I change the code so that all the epochs are included in this Brainstorm fashion?
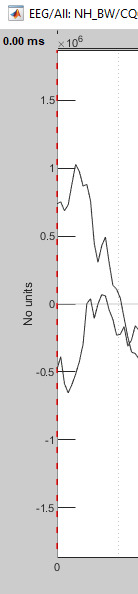
Secondly, when you open each processed file they seem to NOT have a unit (it should be uV) and instead the scale is usually 10^6 or 10^7. How shall I fix this??
I've modified the code several times to include things like Data10^(-6) or Data10^(-7) but then this creates strange issues with units being changed into mV (rather than micro volts) and sometimes it still did not show any units.
How do I change the code so that all the epochs are included in this Brainstorm fashion?
The files are grouped together under a node "trial group" only when they have the same name.
Here they have different names (e.g. WEpoch, Epoch_02...). This tag at the end is added by db_add_data.
One solution is to remove the call to db_add_data, and reload the folder after the end of the loop, using db_reload_studies.
Secondly, when you open each processed file they seem to NOT have a unit (it should be uV) and instead the scale is usually 10^6 or 10^7. How shall I fix this??
You need to fix the values that are save in the file.
All the values in Brainstorm must be in plain international units. EEG values must be saved in Volts.
Therefore all the values you save in the file must be in the range of 10^-6, instead of 10^6 as what appears to be available in your file.
Hello, my apologies for bringing up an old topic but I have a question regarding this post.
Right now this process has been working very nicely without any issues. The screenshot below demonstrates what happens when you input 10 epochs into this process. The process outputs 10 epochs all labelled WEpoch (which stands for weighted epoch).
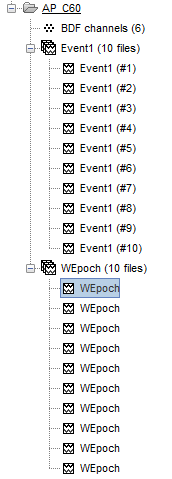
How would I amend the code down below so that each output file now has the Nth number of file attached to it as a tag? I.e. "WEpoch (#1)", "WEpoch (#2)" and etc.
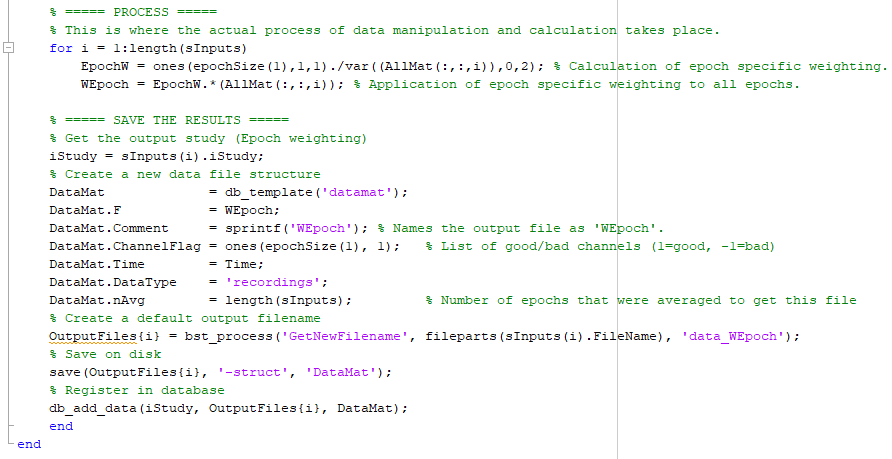
% ===== SAVE THE RESULTS =====
% Get the output study (Epoch weighting)
iStudy = sInputs(i).iStudy;
% Create a new data file structure
DataMat = db_template('datamat');
DataMat.F = WEpoch;
DataMat.Comment = sprintf('WEpoch'); % Names the output file as 'WEpoch'.
DataMat.ChannelFlag = ones(epochSize(1), 1); % List of good/bad channels (1=good, -1=bad)
DataMat.Time = Time;
DataMat.DataType = 'recordings';
DataMat.nAvg = length(sInputs); % Number of epochs that were averaged to get this file
% Create a default output filename
OutputFiles{i} = bst_process('GetNewFilename', fileparts(sInputs(i).FileName), 'data_WEpoch');
% Save on disk
save(OutputFiles{i}, '-struct', 'DataMat');
% Register in database and group them into a trial group node
db_reload_studies(iStudy);
The legend (#iTrial) can be added in the Comment field before.
I.e, in this line of your code:
DataMat.Comment = sprintf('WEpoch (#%d)', iTrial); % Names the output file as 'WEpoch'.
iTrial could be equal to i. However, if each WEpoch files corresponds to each of the trials. it is better to extract iTrial from the input file Comment to ensure that input and its WEpoch file share the same trial number.