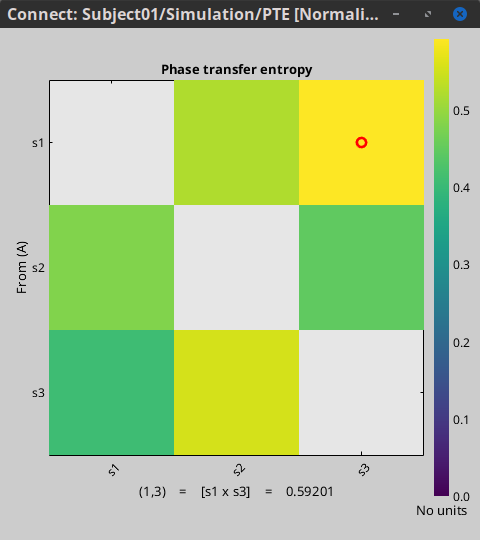
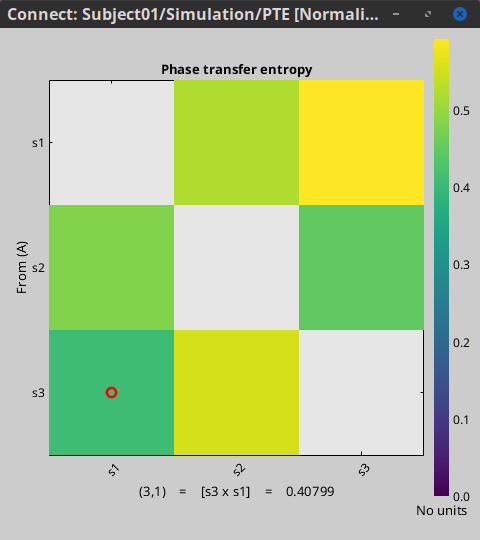
I ran the Phase Transfer Entropy NxN connectivity analysis in Brainstorm on the alpha band and selected the option to Normalize the results. Based on the paper from Hillebrand et al., 2016, the normalization should have results between 0-1, with 0.5 indicating no preferential direction. They provide a range of [0.4892, 0.5108] values for results in 10-13Hz.
The results I got from my data in Brainstorm appear to be centered around 0.515, with no values below 0.5. This was performed during the winter of 2024.
Is the computation correct, and how should this discrepancy in values between Brainstorm output and the Hillebrand et al., 2016 citation be interpreted?
Thank you for the reply. I checked the other forum post and it matches the dPTE computation I would like to perform in Brainstorm.
How would pre-processing affect the normalization equation? I followed the tutorials for all the pre-processing and cleaning (blinks and cardiac). The data is event-related and downsampled to 600Hz.
I thought that selecting the normalization box when running the PTE analysis in Brainstorm will perform the equation dPTExy = PTExy / (PTExy + PTEyx), such that the complementary connections of dPTExy and dPTEyx will have one value above 0.5 and the other below 0.5, unless the PTE values were equal.
Can you try to compute the dPTE with the simulated data from the connectivity tutorial?
With Brainstorm open, run this command: tutorial_connectivity()
It will simulate signals and compute some connectivity metrics, dPTE is not among them.
Once the script ends (~5 min), compute dPTE and verify the normalization.
What is the space of the signals that are being used for dPTE? Source space? Sensor space?
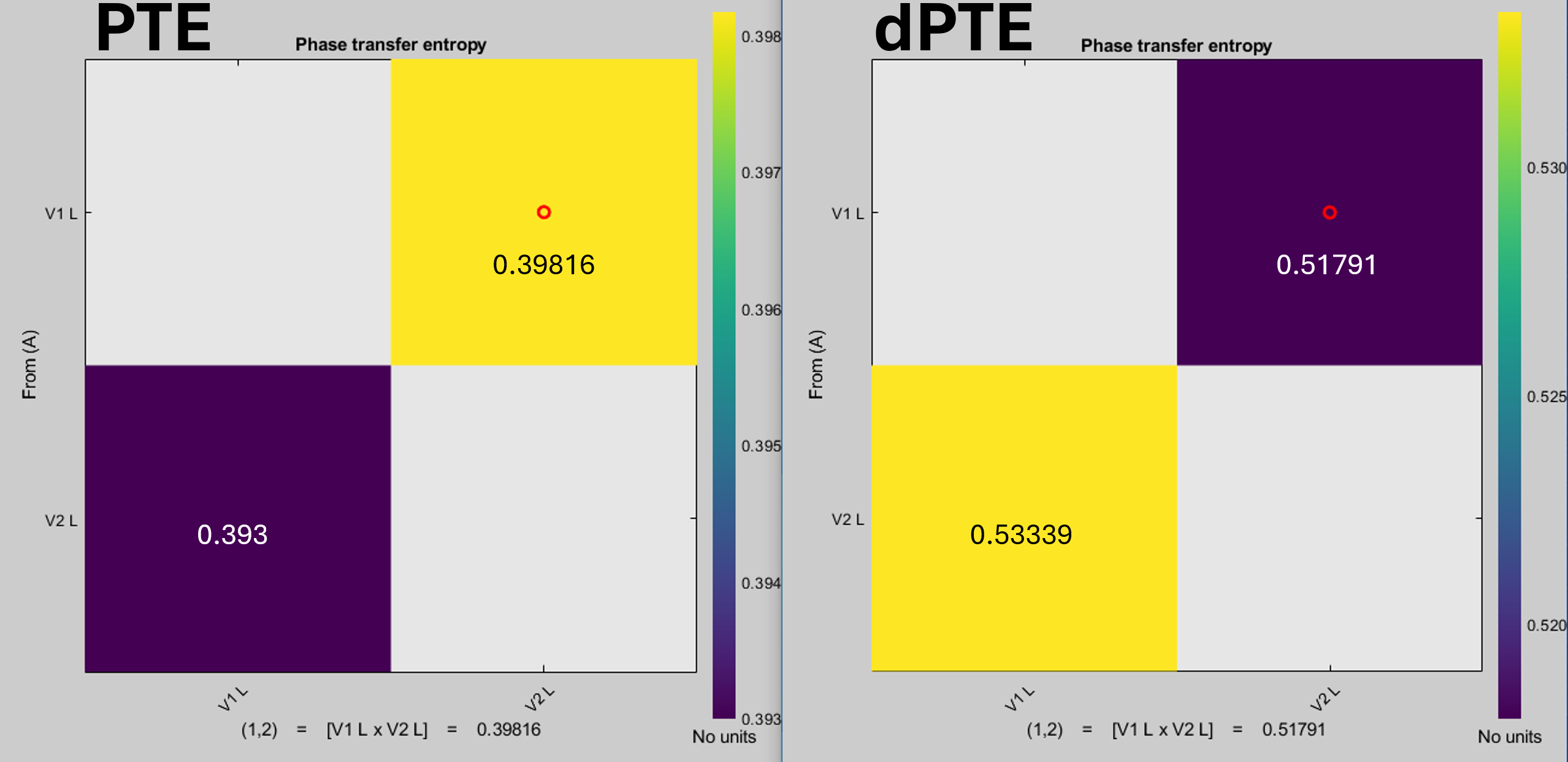
I tried the dPTE analysis with with tutorial data and it worked. Doing the computation in sensor space with my own data also works. The issue is only when trying to use the source space for an analysis between ROIs. I attached a screenshot of the PTE and dPTE results ran this morning. The output doesn't appear to make sense from the theoretical dPTE computation. It's the mean scout function. If I select to flatten unconstrained sources, the output becomes centered at 0.5, but the direction is affected.
The script that runs the dPTE analysis uses the function 'process_pte1n'
Thank you for providing extra information to understand better the situation. It seem you are working with unconstrained sources, using Scouts with the mean function, applied before.
Is this right?
The issue is how the sources and their different orientations are aggregated in the Scout
By doing so, first all the unconstrained sources (3 components per source) get flattened (to one component per source). Then with the Scout function mean applied before, for each Scout, one time series is computed, and with these Scout time series the Scout-to-Scout dPTE is computed. This is illustrated in the first diagram of this tutorial section: https://neuroimage.usc.edu/brainstorm/Tutorials/CorticomuscularCoherence#Method_for_constrained_sources-2
However, if flattening is not used, the processing is a bit different. Each unconstrained source in the scout has 3 components, thus activity in the Scout is aggregated as three time series (one for each orientation). Then the connectivity metric is computed for the nine combinations of these Scout time series (since each Scout consist of three time series). These nine connectivity measurements then are aggregated with the maximum among them to give a Scout-to-Scout connectivity number. This is illustrated in the first diagram of this tutorial section: https://neuroimage.usc.edu/brainstorm/Tutorials/CorticomuscularCoherence#Method_for_unconstrained_sources-2
As you can see, the second way is not necessarily centered around 0.5, because:
dPTE Scout1-Scout2 value is obtained from the maximum dPTE from the 9 combinations [Scout1_x, Scout1_y, Scout1_z] × [Scout2_x, Scout2_y, Scout2_z].
dPTE Scout2-Scout1 value is obtained from the maximum dPTE from the 9 combinations [Scout2_x, Scout2_y, Scout2_z] × [Scout1_x, Scout1_y, Scout1_z].
I hope this makes clearer what is happening once Unconstrained sources and Scouts are involved.
Yes, I am using unconstrained sources with the mean function applied before.
I believe that I'm following along with what you mentioned, yet it remains unclear to me why the simple computation from Hillebrand et al., 2016 is affected by this, moreover, why the results of directionality change. It worked on the sensor level, however, not on the sources. Is the function doing the correct computation: dPTExy = PTExy / (PTExy + PTEyx), and if so, why doesn't the output reflect this? Or is there something else happening behind the scenes?
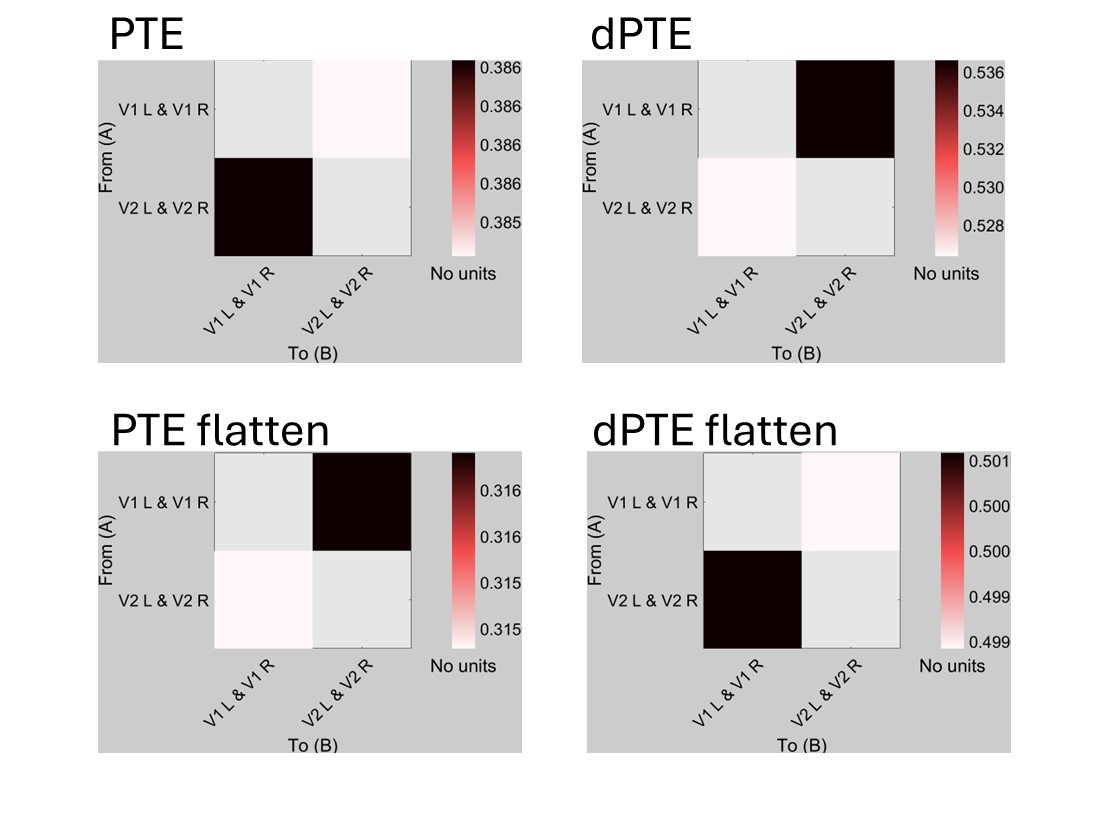
I computed both PTE and dPTE for the unconstrained, and flattened sources and attached them as an image. As seen, the interpretation of directionality is affected, both from unconstrained to flattened, and from PTE to dPTE results. This isn't the case with the sensor level analysis.
This is because the normalization happens before aggregating the results across "dimensions".
Does it make sense? Check the following example:
With unconstrained sources, using the mean scout function before the connectivity:
ScoutA is comprised of 3 time series (ScoutAx, ScoutAy and ScoutAz)
ScoutB is comprised of 3 time series (ScoutBx, ScoutBy and ScoutBz)
With these time series, there are 18 PTE values:
Nine PTE values from ScoutA to ScoutB:
PTE_Ax_Bx, PTE_Ax_By, PTE_Ax_Bz,
PTE_Ay_Bx, PTE_Ay_By, PTE_Ay_Bz,
PTE_Az_Bx, PTE_Az_By, PTE_Az_Bz,
And nine PTE values from ScoutB to ScoutA:
PTE_Bx_Ax, PTE_By_Ax, PTE_Bz_Ax,
PTE_Bx_Ay, PTE_By_Ay, PTE_Bz_Ay,
PTE_Bx_Az, PTE_By_Az, PTE_Bz_Az,
At this point normalization is performed, leading to 18 values of dPTE. For example: dPTE_Ax_Bx = PTE_Ax_Bx / (PTE_Ax_Bx + PTE_Bx_Ax)
and dPTE_Bx_Ax = PTE_Bx_Ax / (PTE_Ax_Bx + PTE_Bx_Ax)
Thus, the final value of dPTE_AB (dPTE from ScoutA to ScoutB) is the maximum of the 9 dPTE from ScoutA_to_ScoutB. In similar way dPTE_BA (dPTE from ScoutB to ScoutA is the maximum of the 9 dPTE from ScoutA_to_ScoutB
The directionality should not change if flattening is used, as there is not need to aggregate across dimensions as shown above. Connectivity between scouts is performed with only one time series per Scout (as it does per sensor, one time series per sensor).
To check the change of directionality:
On bottom left figure, click to verify the PTE values. And compute dPTE from them.
Do the calculated dPTE values agree with the values in the bottom right figure?
Can you extract the Scout time series with the process Extract > Scout time series and compute PTE and dPTE with the resulting matrix file?
The figure I showed in the previous message displays the change of direction. The calculated dPTE values do not match in the bottom row. Unless there is something behind the scenes that I'm missing and you can clarify. For the flattened PTE values (bottom left of figure), PTE_ab = 0.3169 and PTE_ba = 0.31478. Doing the math, it would equal dPTE_ab = 0.501678 and dPTE_ba = 0.498322. The dPTE result (bottom right of figure) has the values of dPTE_ab = 0.49892 and dPTE_ba = 0.50108.
Responding to your second request. After extracting the scouts and doing the analysis on the matrix files, the direction now appears unaffected.
As a follow up question, is the computation affected by selecting the output options: save individual results (one file per input file) versus save average connectivity matrix (one file). The analysis is event related. I would like to get one connectivity result for each participant, then compute a group average. There are approximately 100 events per participant.
Yes, it affects the result. For individual results PTE and dPTE between scouts are compute from their time series. In this case the directionality will not change. In the case of average, the PTE and dPTE between Scouts, are the average of PTE and dPTE obtained for each file; since for each file dPTE, average PTE does not necessarily have the same directionality as average dPTE.
For example, computing the across-files average PTE and dPTE between ScoutX, and ScoutY:
Hi Raymundo, can you please clarify what is the difference between the rows in your example, specifically
The goal for me is to get a result for each participant. Is there a correct, or wrong way to go about this? Such as doing a connectivity analysis for each trial, then averaging the results together, or clicking on the option both to output only the average result when all the trials are in the process box?
Hi @ericmokri, this was a numeric example to illustrate the across-files average of PTE, and the across-files average of dPTE does not necessarily share the same orientation. I have updated the post to make clearer.