I seem to not understand the first question completely.
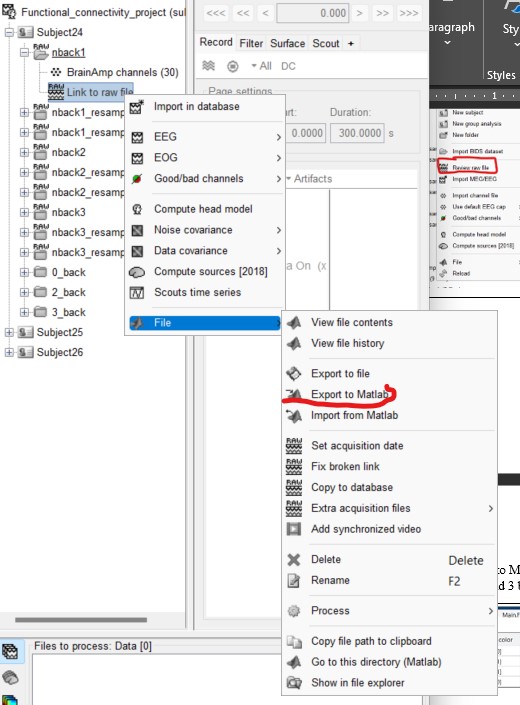
Figure 1 shows a file that was imported with the menu "Import MEG/EEG" (when right-clicking on a subject) or "Import in database" (when right-clicking on a "Link to raw file" already available in the database). This is a full copy of the recordings saved into the database, on which the features only available on continuous files (e.g. ICA/SSP cleaning) are not available anymore.
We do not recommend working with fully imported files like this, this is very inefficient. For working on the creation of your events, you don't need the data to be imported, you only need a "Link to a raw file" (what you get with the menu "Review raw file").
https://neuroimage.usc.edu/brainstorm/Tutorials/ChannelFile#Review_vs_Import
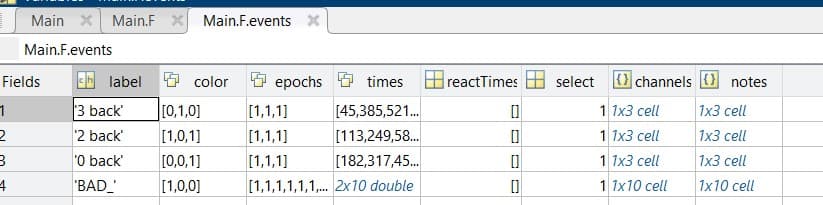
The initial recording had the events in form of single events (with stimulus and responses). So, I created an equally-timed extended event that captures each trial (stimulus and response). I labelled all the recording prior the start of the trial as bad segments so it isn't included in my analysis. Is that the right approach to doing it?
I don't understand why you need to create bad segments.
From the continuous file (rather than the fully imported file), you create extended events, and then you import these extended events as epochs into the database. I don't understand what the role of bad segments is, here.
The only obvious reason I could see would be to compute a PSD from the continuous file using only the "non-bad" segments. Is this what you tried to do?
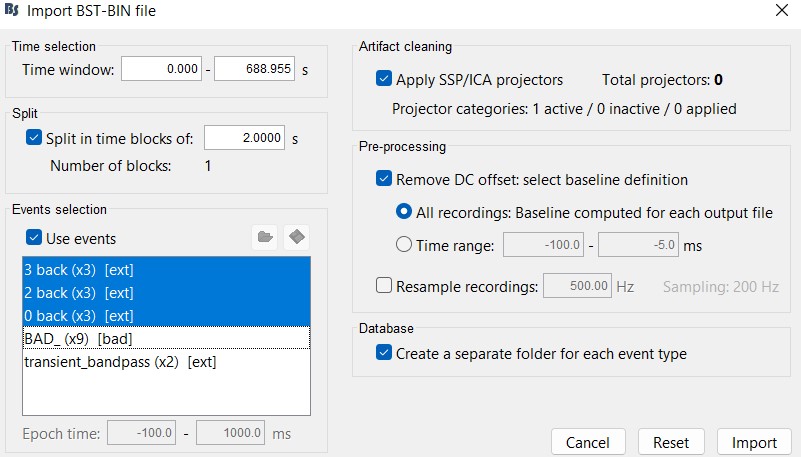
I wanted each trial (0-back, 2-back and 3-back) to be epoched with a length of 2 seconds so I used the "split in time blocks of 2s" option. Does that tally with what you said?
If you expect to get 2s-blocks, your selection of options is correct, no problem.
My concern is more about the use of these 2s-blocks. I've seen many Brainstorm users trying to average short blocks like this, which is most cases makes no sense. What are you expecting to do with them?
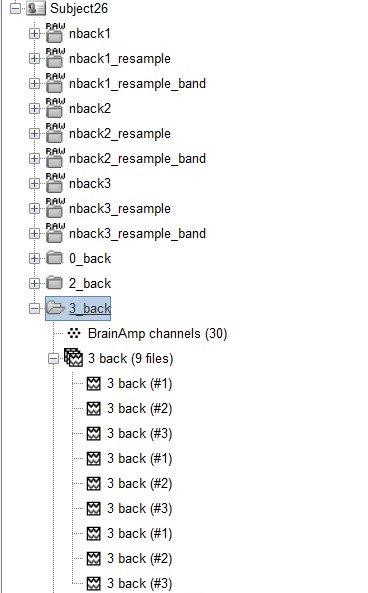
This prompted my decision to have each event in separate folders and then combine all the data in the entire session into one file. Is this the best approach that should have been followed?
This is correct, but only if the channel file is strictly the same across all the recording sessions. Be aware that the channel file includes the SSP and ICA component selection. If you have removed some ICA components independently from each recording session, then the three channel files contain different information. See the field Projector in the channel file : https://neuroimage.usc.edu/brainstorm/Tutorials/ArtifactsSsp#On_the_hard_drive
The imported trials are all correctly cleaned with the correct information, but if you group the trials from the 3 recording sessions in the same folder, then the description of the removed components becomes inaccurate (or more precisely, only one channel file - and IC selection - is kept and considered to be applied on all the trials).
This has no impact if you work only at the sensor level (computing averages, statistics, time-frequency, connectivity measures). However, if you are expecting to do some source estimation from these recordings, this might cause some unwanted biases: the mixing matrix corresponding to the IC selection (saved in the Projector field of the channel file) is applied to the forward model before the computation of the inverse model. This might result in applying the wrong mixing matrix for two of the three recording sessions. This impact is possibly very minor, but formally, it still better to avoid it.
I apologize for the complexity (and possible lack of clarity) of the explanations above.
The take home message is simply: if you used ICA for cleaning the artifacts AND you want to estimate sources for these recordings, prefer NOT using the option "Create a separate folder for each event type". In all the other cases, what you did is OK.
Additional comment about preprocessing:
I think I would have preferred a different solution for the order of the preprocessing:
- band-pass filter (the higher the sampling frequency, the better the result of the filtering), then
- Import with the resampling option selected.