Hello Brainstorm,
I would like to use the "export to file" function within a pipeline and/or as part of a script to analyse and export data as ".csv". I note that "export to file" isn't available as a separate brainstorm process (am I correct in this?).
Is it possible to use the "export to file" function in this way and if yes, how would I achieve that?
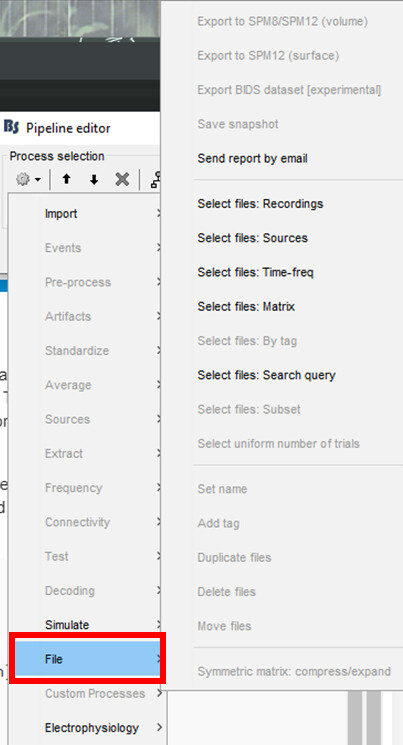
Edit: This is already a process in Brainstorm (added on 13-dec-2023) Process1 > File > Export to file
The GUI option Export to file calls different functions depending of the type of node.
To know which function you need, search for the string 'Export to file' (with single quotes) in the tree_callback.m script to find the one you need. Otherwise, you could indicate in this post which file type is the one you want to export.
Thanks for the reply Raymundo.
The two file types that I require are ".csv" (ASCII: Comma-separated) and Microsoft Excel (".xlsx").
The plan is to use it within a context like the below code. The idea is to select for a Subject > Condition > Event type > Run process > Export to a location. Therefore I would need the export function code just after the "Extract values: C3" process.
On a related note, are there any plans in the future for the export to files (or export to MATLAB) function to be added as a separate process under "File"? (like the screenshot below) This would make generating scripts (and adding processes under the pipeline) extremely easy for the users.
Thank you for the suggestion. A process to exporting to files sounds like good idea, it will help with the proper call of the different export functions. About the Matlab, there are low level functions such as in_bst_(data / results / timefreq / matrix) that do the trick.
Edit:
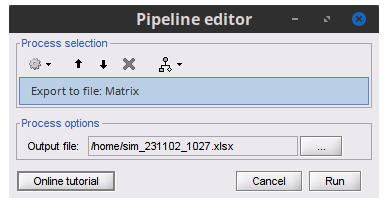
For the moment, to export a matrix, you can use the function
Hi @Raymundo.Cassani thank you very much for doing this!
This looks great, I've just tried it with a couple of my own data sets.
Two ideas for feedback are as follows:
When you load the process in the pipeline editor maybe a description of the process could be helpful. For example how the process takes in only one file.
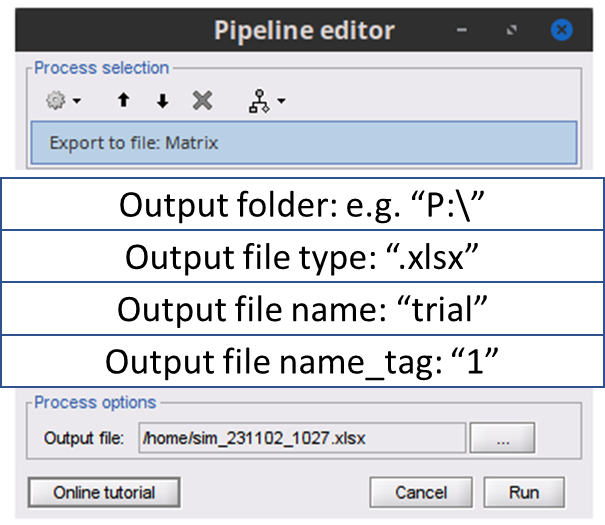
Maybe it would be better for the process to be able to handle many files at the same time. That is, rather than having the current layout it might be better to have the below layout.
Output folder is where the file will be saved. Output file type is the type of file (.csv .xlsx so on). Output file name is the name of the file before file type (trial.csv). Output file name_tag is any tag that should come after the name of the file - especially in cases where there are numerous trials or outputs e.g. trial_1, trial_2 etc.
Yes, this is needed. As well as an entry in the [Scripting tutorialhttps://neuroimage.usc.edu/brainstorm/Tutorials/Scripting)
I thought about it. This are the reasons why I did not follow that path:
It can lead to confusing in the output filenames. For example, if the user puts Data files that are not necessary from the same trial groups.
To avoid this the output filename could be set to be the same as the file in the Brainstorm database. But this removes the option of setting a meaningful filename for the output files. This is the default behaviour for the right-click (on trial group) > File > Export to file, outfiles have the name of the files in Brainstorm dataset.
Thus, exporting multiple files would be done by using this process in a FOR loop, the user will have full control on the output filename for each input file.