Sorry if this is a silly question; I'm new to Brainstorm. I have .edf files for some sEEG data and I am using MNE to preprocess it. From what I've seen thus far, the only options are MEG/EEG or EEG import file formats; to import sEEG, I have been using the
'review raw file' - SEEG: Deltamed/Micromed/NK/Nicolet/BrainVision/EDF
When importing my raw edfs, I get a message from Brainstorm to convert these to continuous format. However, when I preprocess using MNE, the .edf files produces are obviously not continous, and no such popup window is given. I'm wondering if there is a flag in the file that needs to be present for Brainstorm to know whether it is continuous or not? Or if there is an option to do this manually after import? Or, perhaps, there is another way to import the data that would be more appropriate?
In case anyone is wondering what I've done to it in MNE:
import mne
# Read .edf into raw MNE format
data = mne.io.read_raw_edf(input_file + '.edf', preload=True)
# Scale the data so it readable by MNE; the data recordings seem to upload in microvolts
data.apply_function(lambda x: x * 1e-6, channel_wise=False)
# Crop file to movie timings
data.crop(tmin=56.202, tmax=376.216, include_tmax=False)
# Average re-referencing (exclude trigger channels)
real = data.ch_names[5:]
data.set_eeg_reference(real, projection=False)
# Resample to 1000 to correct rounding error of 0.0000000000001 on sampling rate
data.resample(sfreq=1000)
# Export preprocessed data file to .edf
mne.export.export_raw(output_file + '.edf', data, 'edf', overwrite=True)
Any help on this would be much appreciate, thanks!
This is correct, this option will read the sEEG data with the correct format based on its extension. By using this SEEG option, Brainstorm will automatically treat the channels as sEEG, rather than EEG.
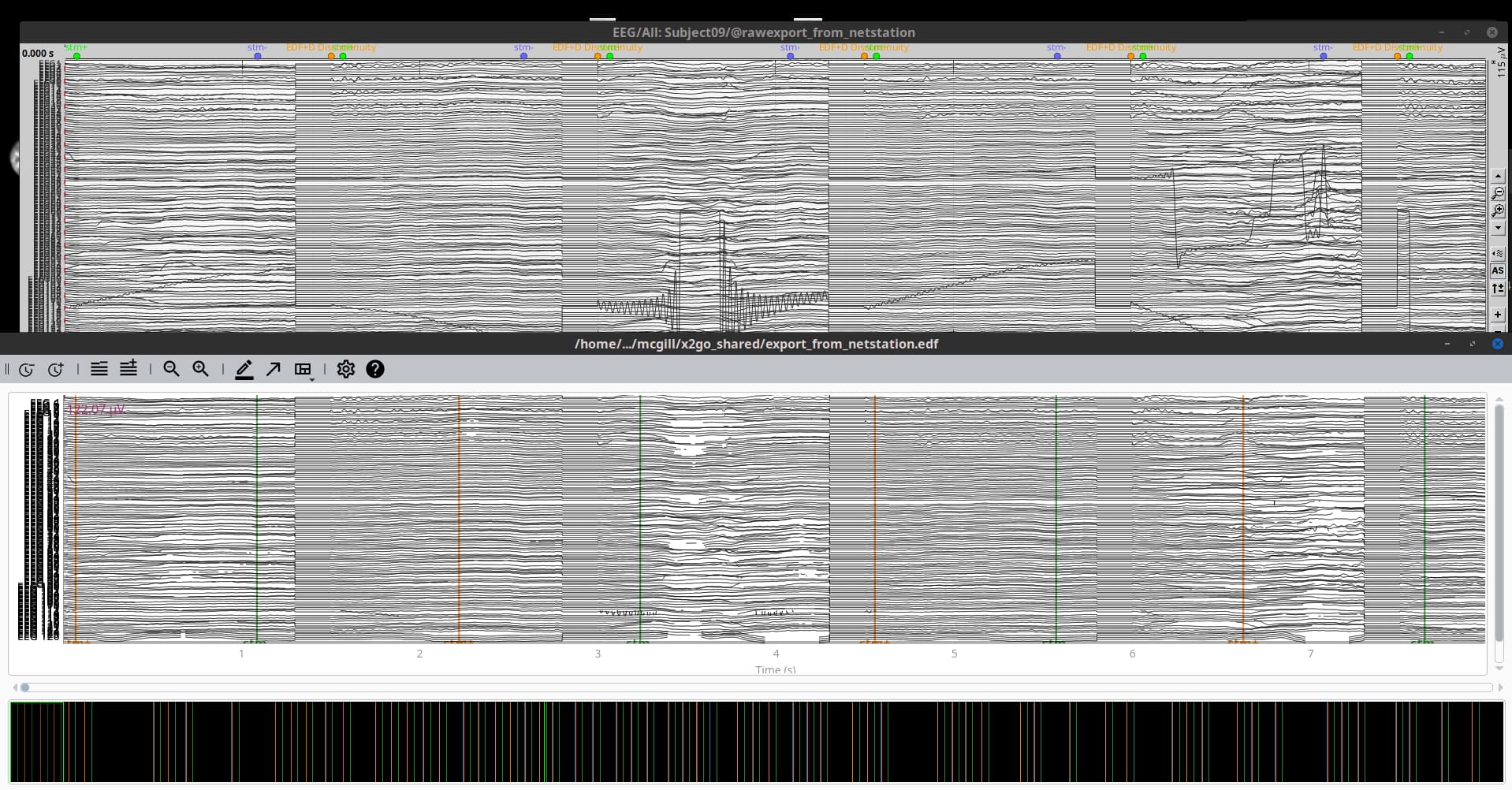
This happens when the data is saved as EDF+D which means that the recoding is discontinuous with interruptions between consecutive data records. Is this the case with your data?
When this kind of data is imported in Brainstorm, all the data gets concatenated, and events called EDF+D Discontinuity are added to show where the data has not continuous.
I tried the lines above with a EDF+D file that I had at hand, and similar to Brainstorm, the data is read in the continuous way. However, it seems in MNE-Python the timing of the events in discontinuous files is not properly handled.
This is not what I see with my data at hand, the EDF+D is read as continuous EDF in MNE-Python, then after processed it is exported as EDF+C (continuous), and this is why once you import it in Brainstorm, it does not showed the message about being discontinuous, as it was changed in MNE-Python
The EDF files have information in their headers to show if they are continuous or discontinuous. You can read the first 200 charcters of the file to check this. If in Linux, run in the terminal:
head -c 200 file.edf
It will show the identifier EDF+C or EDF+D
Since the event timing seems better handled in Brainstorm. You could import your data and do the same pre-processing in Brainstorm without any trouble.