Greetings,
First, thanks for all the hard work that has been put into this toolbox and maintaining this forum.
I would like to bring attention to an issue I encountered regarding the normalization of the power spectra.
When looking at the power spectra, I specified that I wanted to look at both the full alpha band (8-12 Hz), in addition to high (8 - ~10) and low (~10 - 12) alpha separately. I also extracted the usual frequency bands in addition (delta, theta, beta, gamma). So, Brainstorm outputs the 7 frequency bands: delta, theta, alpha, alpha1, alpha2, beta, gamma.
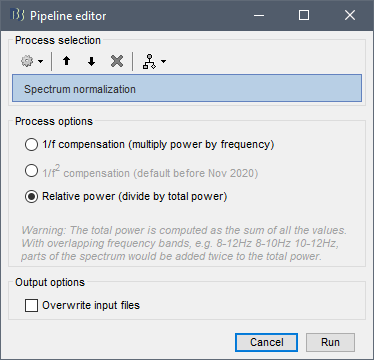
I also selected the option to normalized this spectral information. While I assumed the spectrum would be normalized based on the full spectrum (or, at least up to a certain cut-off; e.g. 80 Hz), I discovered that this is not the case. Instead, each of these 7 frequency bands are normalized based on only these 7 frequency bands, by adding the power in each together as the total power to normalize against. In this case, the full alpha band in addition to the high and low bands ALL go into the normalization - alpha is essentially counted twice.
I do not mean to say that using the band-limited information for the normalization is inherently incorrect. However, I found that the documentation did not make immediately clear that this is how normalization was being handled. I think other users may feel similarly, particularly if not using the full spectrum and only looking at any particular frequency band (i.e. omitting delta, or only looking at alpha).
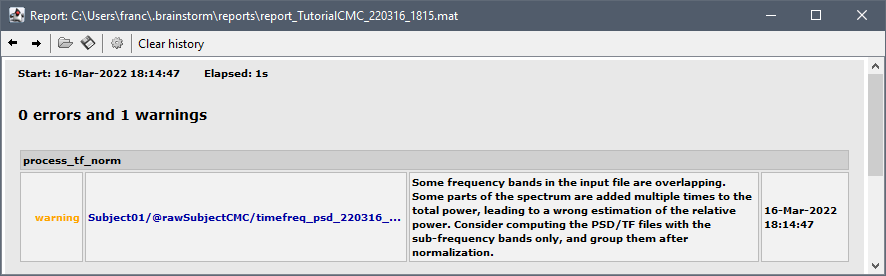
More to the problem, I was surprised that the normalization process in brainstorm did not account for overlapping frequency bands (i.e., full alpha, low alpha, and high alpha), and prevent overlapping frequencies from being counted twice. I do understand that within Brainstorm I could have alternatively first normalized the spectrum and then averaged within frequency bands to avoid this issue. But, again, I feel that this should be made clear in the documentation considering that looking at full- and sub-bands is not uncommon, especially when exploring the data.
Can this normalization process be more clearly documented in the tutorials?