I was wondering if you would have any solutions to the following problem. Our experiment has four different conditions (dual-task, single-task, walking, and rest). I am trying to obtain an average/sd HbO figure for each condition across all participants. So far, I've tried to do this in two ways.
The first way, is I obtained an average file for each participant (I attached the dual task average figure for one participant as an example) and then I would try to average those files together across participants. However, when I do this, I get an error message indicating that the matrices have different sizes. This might be due to the fact that I ran some pre-processing steps prior to averaging the trials, which may result in a different number of matrix rows for each participant file.
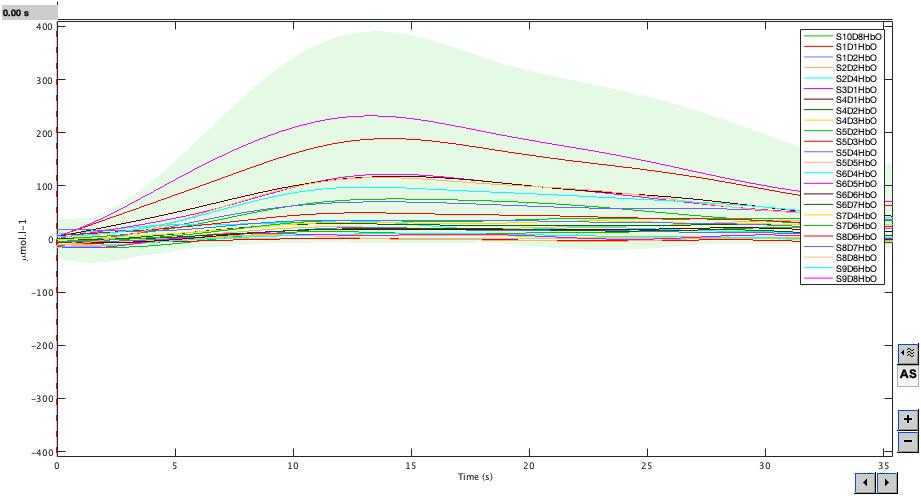
The second way I tried doing it was by inserting the individual participant dual-task trials in the processing toolbox and averaging them together (rather than averaging the average files). This resulted in some strange looking figures (attached an example). I was wondering if there was an easier way to obtain the average HbO across participants for a specific condition? Please let me know if you happen to have any suggestions.
Indeed, you can only average together files that have strictly the same number of time samples and the same number of sensors. The channel names and their order between files must match across all the input files. The same problem is common in EEG, where some preprocessing steps done outside Brainstorm may drop some bad channels completely.
If you have different numbers of channels between participants, you may try to select all the subject averages in Process1 run the process "Standardize > Uniform list of channels". Make a full backup of your database before trying this, as it would rewrite the channel files and all the files related to them (including the single trials located in the same folder). This has to be executed immediately after import of this epoch, as it would break all the files computed from the recordings (time-frequency, PSD, sources...). If something bad happens during this step, it can damaged permanently your database in a non-recoverable way.
To minimize the impact of this process, maybe you could for each subject create a new folder "average", copy the subject-level averages to it together with the channel file, and select these copies of averages in Process1 to run the process. This could minimize the impact on the database. It would work only with the subject configured with the option "Default channel file: NO".
The second way I tried doing it was by inserting the individual participant dual-task trials in the processing toolbox and averaging them together (rather than averaging the average files). This resulted in some strange looking figures (attached an example).
Something is not aligned between the different subjects... Maybe the channel order is different?
I would not recommend this approach anyways, as we recommend using weighted averages between runs for each subject, and regular averages between subjects. See this the two parts of the Group analysis tutorial: