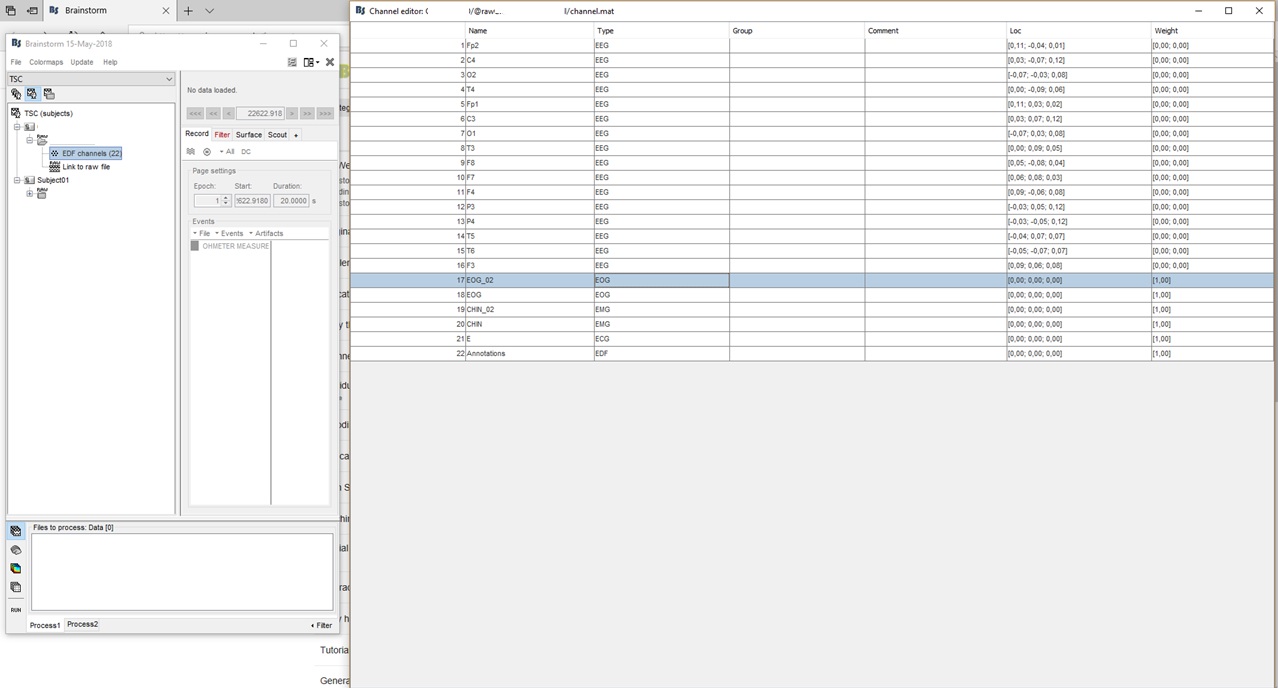
I'm tryng to analyze an .EDF file registered from an EBNeuro machine. 22 channels (16EEG, 2EOG, 2EMG, 1 ECG, 1 edf annotations)
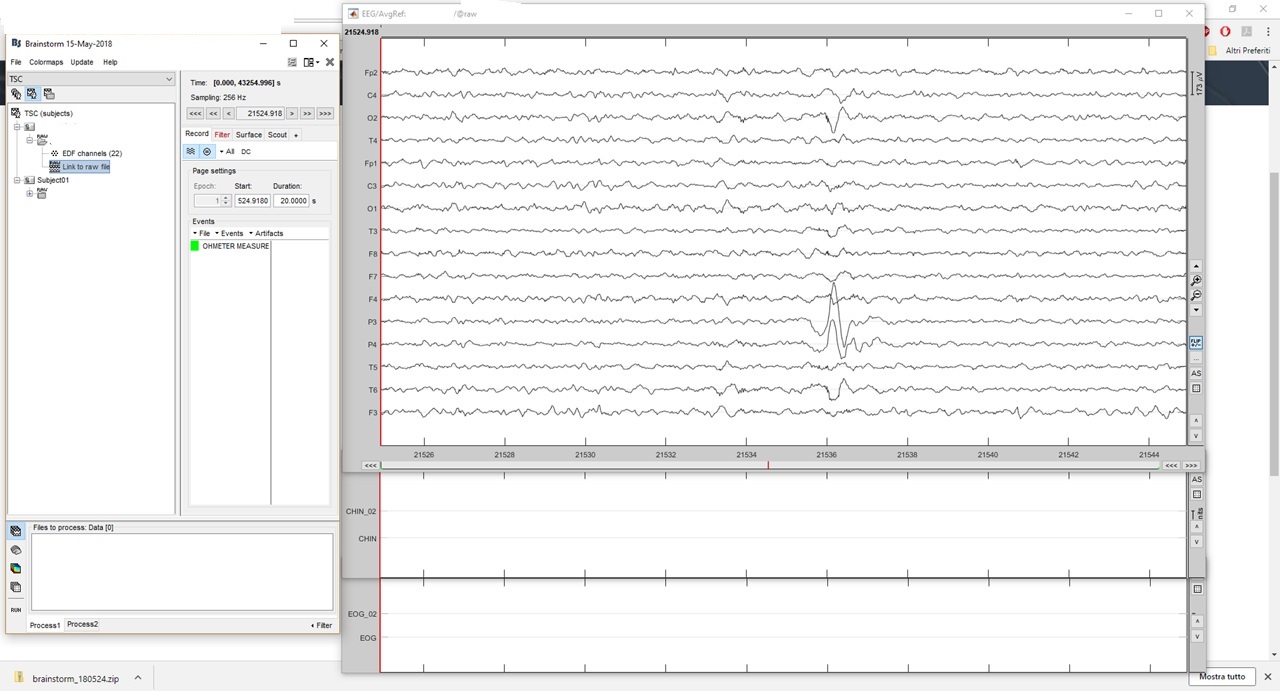
I can normally view EEG tracks, but nothing for both EOG and EMG and ECG.
Are you sure you have signals correctly recorded in these channels?
Does it look any better if you display only one channel type at once (eg. only EOG).
“No units” means that the units could not be identified automatically (in uV for instance), typically either because there is no signal at all or because the values are too high to be physiological signals (> 0.1V for instance).
Another source of problems with EDF files are mixed sampling rates. I don’t remember if Brainstorm handles this correctly. Is there any chance your EMG and EOG were recorded at different sampling rates?
You can check this by looking in the header of the .edf files, saved in the links in the brainstorm database. Right-click on the “Link to raw file” > File > View contents.
If you really don’t understand what is going on or your suspect Brainstorm to behave incorrectly, please send us an example file so we can have a look at it. Upload it somewhere (google drive, dropbox, etc.) and post the link here.
I think signals (EOG, EMG, EKG) are correctly recorded (can normally view on Galileo suite and other sleep staging software).
Actually EDF file has different sampling rate (EEG and EMG 256 Hz, EOG and ECG 128 Hz), I had to set values down due to limited storage volume of our old portable recording hardware.
Next week I’ll try to analyze a file with same sampling rate, otherwise I’ll try to export tracks in another format (in hypothesis were a specific EDF problem).
If both tests will fail, I’m gonna update you and send an example file.
I checked the code, and channels with lower sampling rates are indeed ignored when reading from EDF files in Brainstorm. This is probably why you don’t see anything in the EMG and EOG windows.
Brainstorm can’t handle signals with mixed sampling rates. It would be possible to reinterpolate the signals with the lower sampling rates using a higher rate, but it would require some consequent rewriting and testing of the current reading functions.
If you are interested in working on this, you are more than welcome than welcome to contribute to the project!