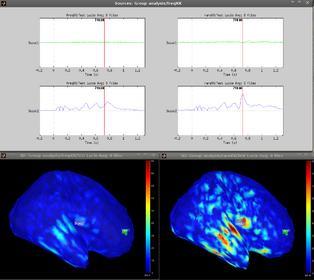
I was trying to use Student t-test (Paired, abs) on my data (8 subjects) but I was very surprise by the results I obtained and in particular by the t-maps (no thresholding, see attached figures) of the difference between my two conditions.
The first figure shows my two conditions (condition A :left column and B right column,). Condition B shows a great increase in activation compared to A in auditory cortex regions. This is confirmed if we put a scout in this area (Scout2, graph on the middle row), compared to a scout in unactive regions (Scout1, graph on the top raw).
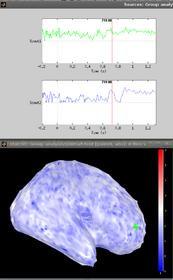
However, in the second figure, you can see that the t-map (not thresholded, uncorrected) don't show this effect at all. This is confirmed if we look at the same scouts where we can see that the unactive scout has as large t-values as the active one.
I know that stats can be be sometimes surprising (!) but this result seems highly unplausible for me. Furthermore, I obtained similar results with another set of data.
Did anyone else have a similar problem ? Could it be a bug in computation of the t-maps ?
I agree there seems to be a strong difference between A and B at the latency your are showing in the auditory regions. It’s a bit hard to rule out the possibility of a bug without me looking at the data a bit more closely. In the first figure you are showing, I cannot read the color scales in each figure: please make sure they are scaled to the same maximum.
Also, please bear in mind that a sample size of 8 is pretty small, hence the t-test might not be sensitive enough and the underlying hypotheses might not hold (normal distribution of measures, essentially). With such a small sample size indeed, you need to make sure the strong difference in B is not due only to one subject as an outlier (review each individual data separately).
Please send an update after you have reviewed these issues a bit further.
I am wondering what’s the validity of a T-test on positive values obtained by taking the abs value.
Maybe a non-parametric rank test like wilcoxon (ranksum.m) would be more appropriate.
This is another issue relating to using t-testing on non-Gaussian distributions (small sample size + rectified values). Wilcoxon would be a bit better (for rectified values) but would still require a larger sample size, ideally.
Permutation techniques would be ideal for handling non-normal samples, although the number of possible permutations would still be quite low: 2e8 = 256.
Good question. Of course, the more is always the merrier but it’s certainly not the point.
In Dimitrios’ paper, we ran simulations to validate the approach with a sample size of 100 (single trials, not subjects) and 1000 permutations. Of course this is usually not realistic when measures are subjects, not trials. If I am not mistaken, 10 subjects would let you combine about 1000 possible permutation pairs, which is a "significant’ plus for only 2 more subjects in the pool (provided these are good subjects, not experimental outliers, but that’s another story/study).
Lucie: what are the chances that you include a couple more subjects? Another remark: what happens when you lower the threshold on the t-map to down to p<0.1 or higher? Do you see a trend of the auditory regions popping out of the threshold?
I agree there seems to be a strong difference between A and B at the latency your are showing in the auditory regions. It’s a bit hard to rule out the possibility of a bug without me looking at the data a bit more closely. In the first figure you are showing, I cannot read the color scales in each figure: please make sure they are scaled to the same maximum.
Also, please bear in mind that a sample size of 8 is pretty small, hence the t-test might not be sensitive enough and the underlying hypotheses might not hold (normal distribution of measures, essentially). With such a small sample size indeed, you need to make sure the strong difference in B is not due only to one subject as an outlier (review each individual data separately).
Please send an update after you have reviewed these issues a bit further.
Thanks!.[/QUOTE]
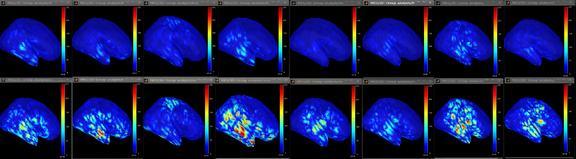
I answer for Lucie. Here are the snapshots of the data for all subjects at the same scale (max = 60) for the two conditions (freqXX and rareXX). As you can see, the difference looks quite reliable for all subjects. I also attach the two averages (scale max = 100) and the paired t-test (uncorrected, thresholded at 0.01) at a time where the difference is maximal between the two condition in temporal cortex.
(I must say the jpegs are pretty small in size. Francois: Do they get resized by the forum server?)
Indeed, it seems there is a trend, athough not as identically distributed among the 8 subjects. Subject #3 for instance shows no effect in the superior temporal region. Subject #8 has strong responses in both conditions. This is all fine but it just illustrates that the sample size needs to grow a bit to account for the variability in your group. This is true for every study of course.
It seems I can see some colored spots on the thresholded t-map, especially in the superior temporal area. Does this means there are some voxels that show significant differences in amplitude? You’re looking at p<0.01: a map computed at p<0.05 uncorrected would be a good start. Don’t expect a corrected map to show much with 8 subjects only: the basic t-test with FDR adjustment would not help much, again because the group size is probably too small.
Please send an update with a map @ p<0.05 so that we can better appreciate the trend. If you see effects in the ST area, I think this would reflect properly the insight we’re getting by looking at the individual data.
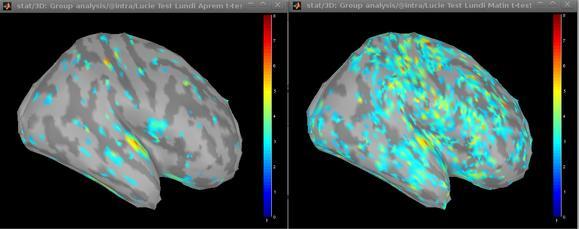
I think Alex was right : the strange look of the t-maps was due to the absolute value option. It shifts the baseline and it finds too high t-values for region where there is mainly just noise. Here is a figure with abolute option on the right and relative-values on the left, uncorrected, thresholded at 0.05. Even if it's still a bit noisy, it makes much more sense.
But it's true that if you look at the effect in each subject (the same figure that catherine gave but with slightly better scale, condition freq on the top and rare on the bottom), we see that the stats are really poor compare to the effect. And of course everything vanishes when we correct for multiple comparison.
What would be you advice to test the difference between the two conditions knowing that we won't have more subjects (more were tested but not all of them could be used for source reconstruction)? Will wilcoxon test be implemanted in bst ? If not, using just t-test, what would be a good strategy ? I was thinking about averaging on a time window of interrest, and test on that, to reduce the problem of multiple comparison ...
It looks indeed better when the test is applied on relative values. Looking at all 8 subjects individually, I would be quite happy with what the stat map is showing at this point (if what is revealed in the superior temporal region is of interest with respect to your hypothesis). I don’t think Wilcoxon would help further either in terms of revealing a much broader or other regions. Averaging on a time window would be similar to low-pass filtering the time series. If timing is not too critical in your study, this would help reduce the variance in your sample. What are the current filter settings and what is the latency you are looking at?
Finally, I don’t think correcting for multiple comparisons would be critical with a group of 8 subjects (again, because of issues with sample size, which impedes what you can infer from the data), but I could be wrong. Thinking positively, this ultimately should not prevent your from publishing your results (also, a group of 8 is small enough to show the individual effects in the body of the publication, or as supplementary material).
replying to Lucie, a wilcoxon test would also give you uncorrected p-values so would not solve the multiple comparison problem. I would go non-parametric but as sylvain said it might not be required.
I tried to look a bit into the permutation tests and apparently there is one in brainstorm (process_permtest.m) but it’s not available for source data.
I was wondering why it was not usable : is it not appropriate for sources ? Is it still supported in the new version of BST ?
Hi Lucie,
There was a permutation function in Brainstorm previously, but it required to load all the data tested in memory, and then required gigantic amounts of memory to run. It may be ok for the sensor-level data, but impossible with the sources.
Those functions have to be completely re-written and optimized to work with the current version of Brainstorm, and to handle a computation by small time blocks instead of processing the full time series at once. The function process_permtest.m is not properly running at this time.
This will be done at some point, but not before the end of the year.
Francois