We are analysing EEG data from 30 subjects from an associative memory task. The data is divided in two groups, hit-trials (represented with a 1), where the subject succeeded in the task, and miss-trials (represented with a 0), where the subject did not. So, for example, for subject 1 there are 167 0-trials and 234 1-trials.
We are aiming to calculate time-resolved phase amplitude coupling, averaged over subjects, from both type of trials separately, to later assess if there are any decreases or increases in this tPAC from hit-trials to miss-trials.
However, given the conditions of our analysis, we want to calculate tPAC individually for every trial, then average individually for every subject, and then average tPACs over subjects, and we are facing some complications. We will provide examples only for subjects 1 and 2 in order to simplify it.
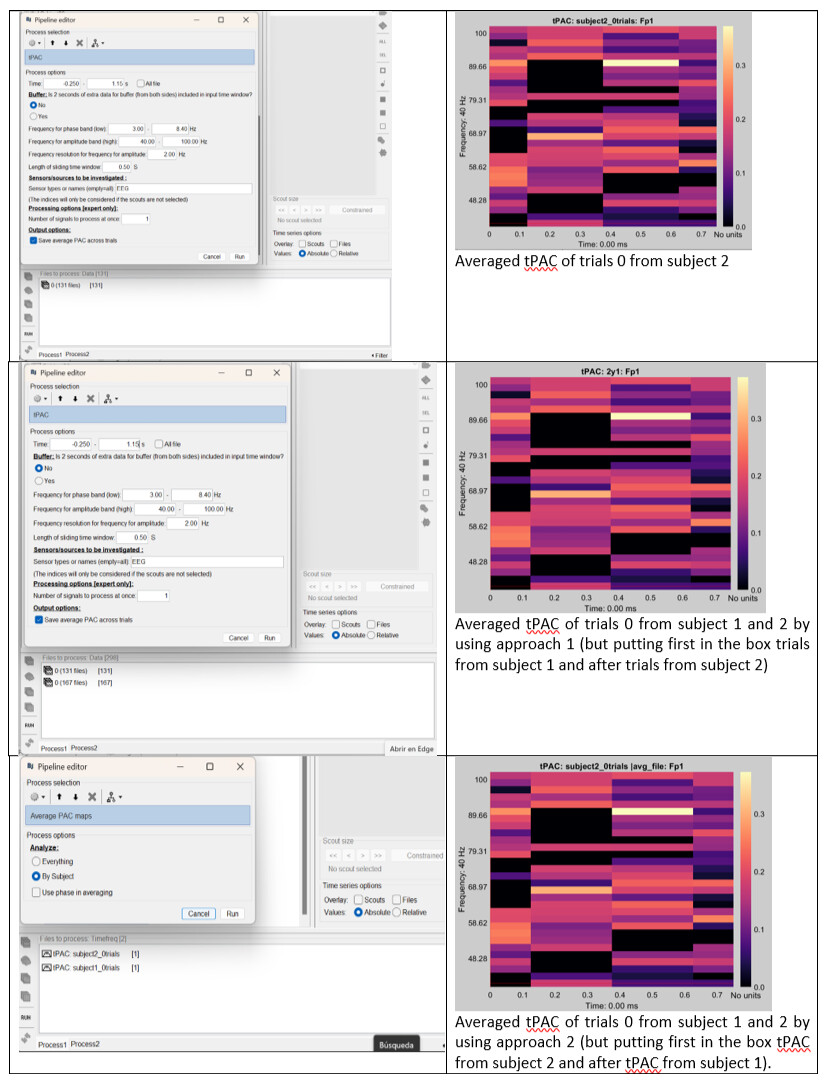
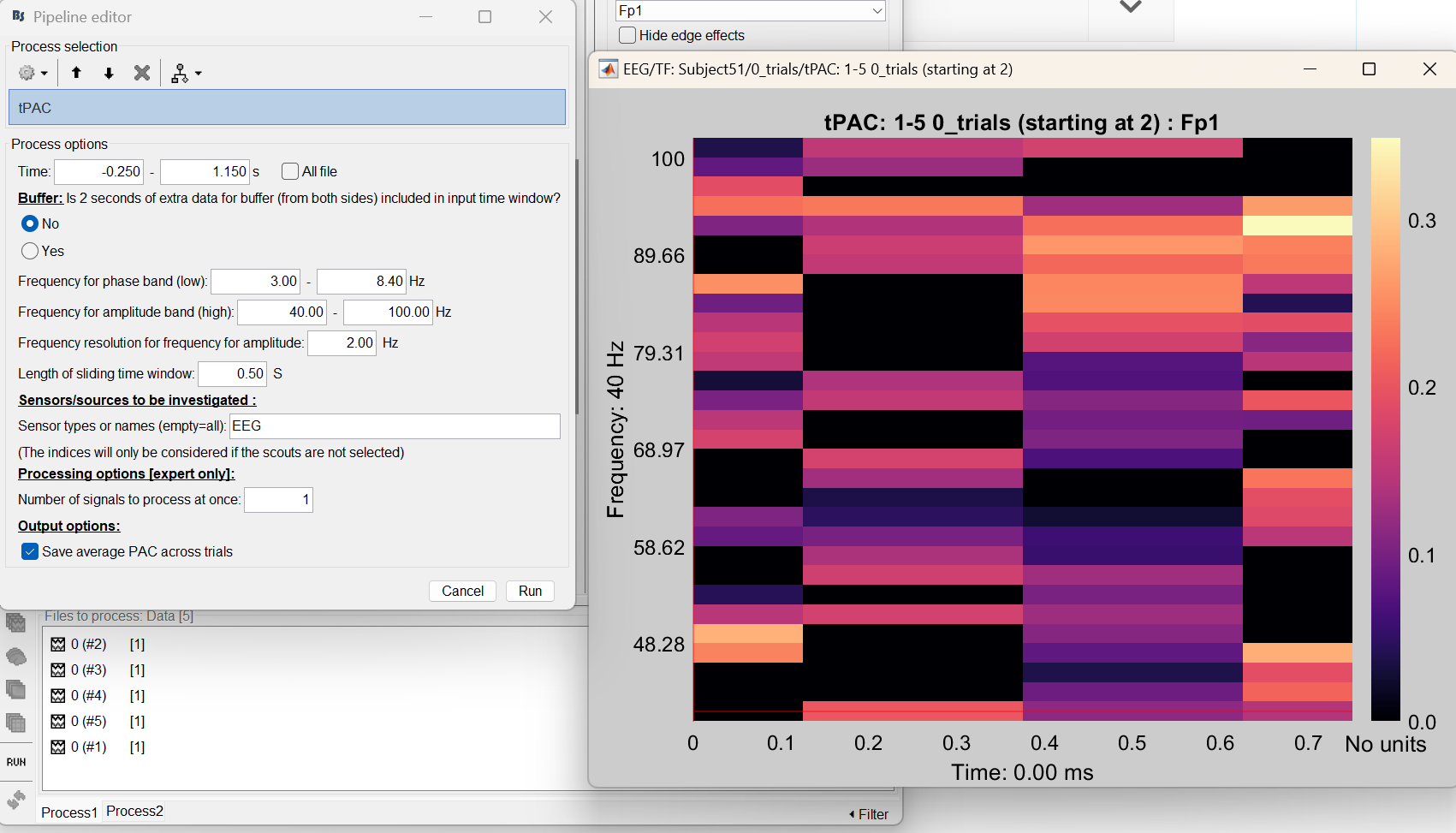
Our first approach was to put all trials, from both subjects simultaneously, on the Files-to-process box and doing the tPAC by keeping enabled the “Save average PAC across trials” option.
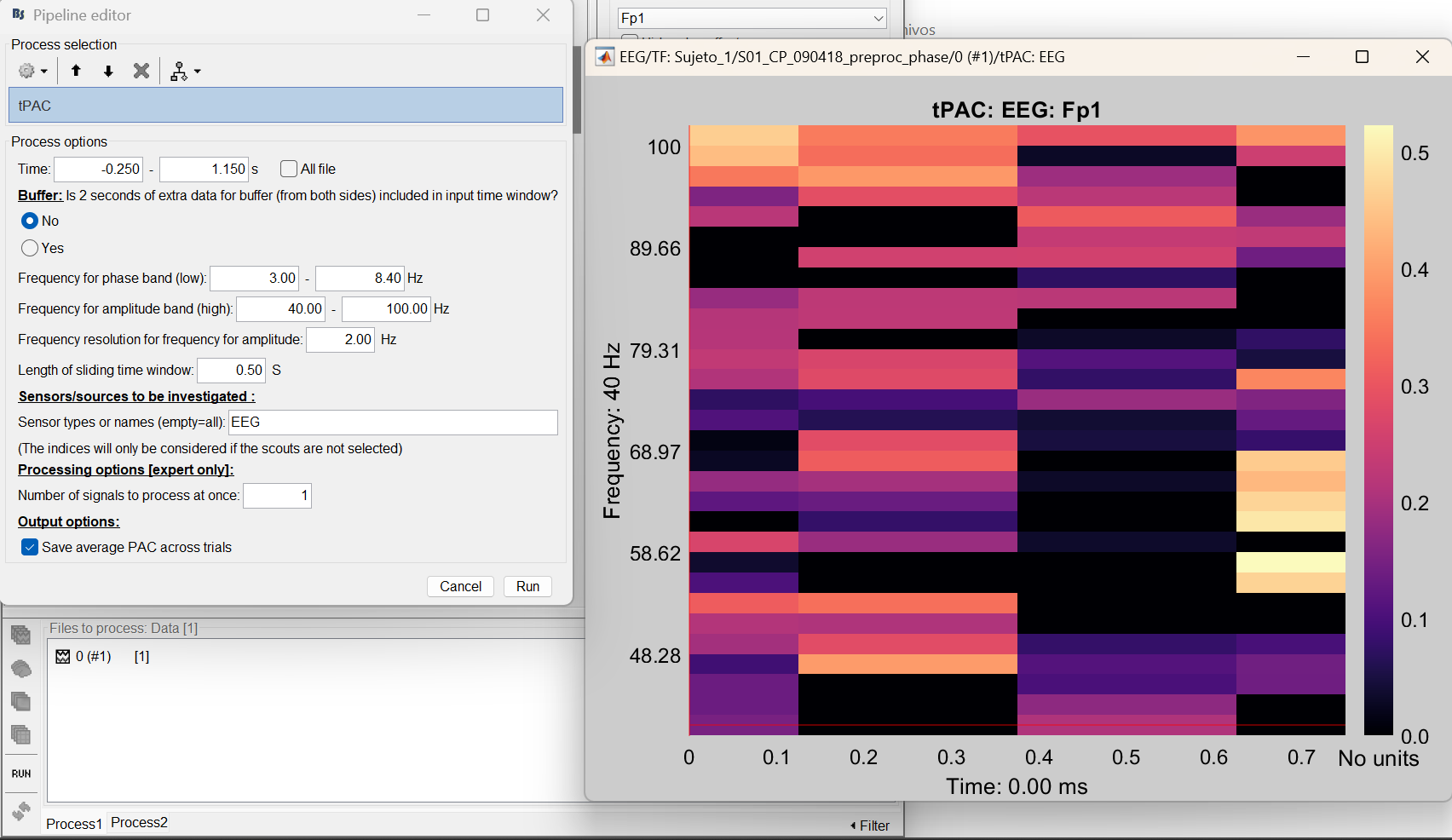
Our second approach consisted on calculating individually tPAC for every subject, hence doing the same as above but putting on the box only 0-trials from subject 1 and obtaining the tPAC map for subject 1. Then, we did the same for subject 2 and averaged both tPAC maps with the “Average PAC maps”.
We realized, first, that both approaches were giving the same results, which made sense to us. However, secondly we realized that these results depended on the order in which we include the files in the box. We attach below a table with, at the first column, the analysis performed and, at the second column, the results obtained for each analysis.
It can be seen that every result obtained corresponds only to the first file included in the box. We wonder if we are doing something wrong or if there is a correct way to perform the analysis we are aiming which is not the one we are using.
Quick comments: In your approach 2, average PAC "by subject" means 1 average result per subject. I think you're trying to average subject 1 and 2, in which case you should select "everything" I think.
For 2nd image middle figure: I think you mean here you put trials from subject 2 first (error in caption)?
For the approach with all files as input, are you sure you're opening the right result? I checked that it is supposed to average everything (not by subject), which means it would save it in the "group analysis" folder. It's strange that it displays "subject1_0trials" in the figure you show.
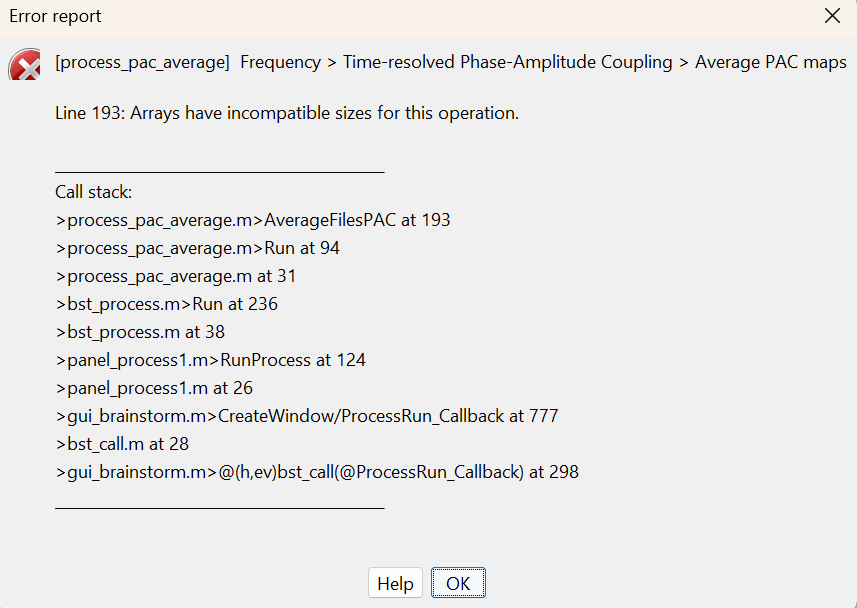
The first comment makes totally, sense so I guess that's a wrong approach given our aim. However, when I try to average using "everything" I obtain the following error, eventhough I used the exact same configuration for obtaining both PACs.
Regarding your second comment, yes you're totally right, it was an error in caption.
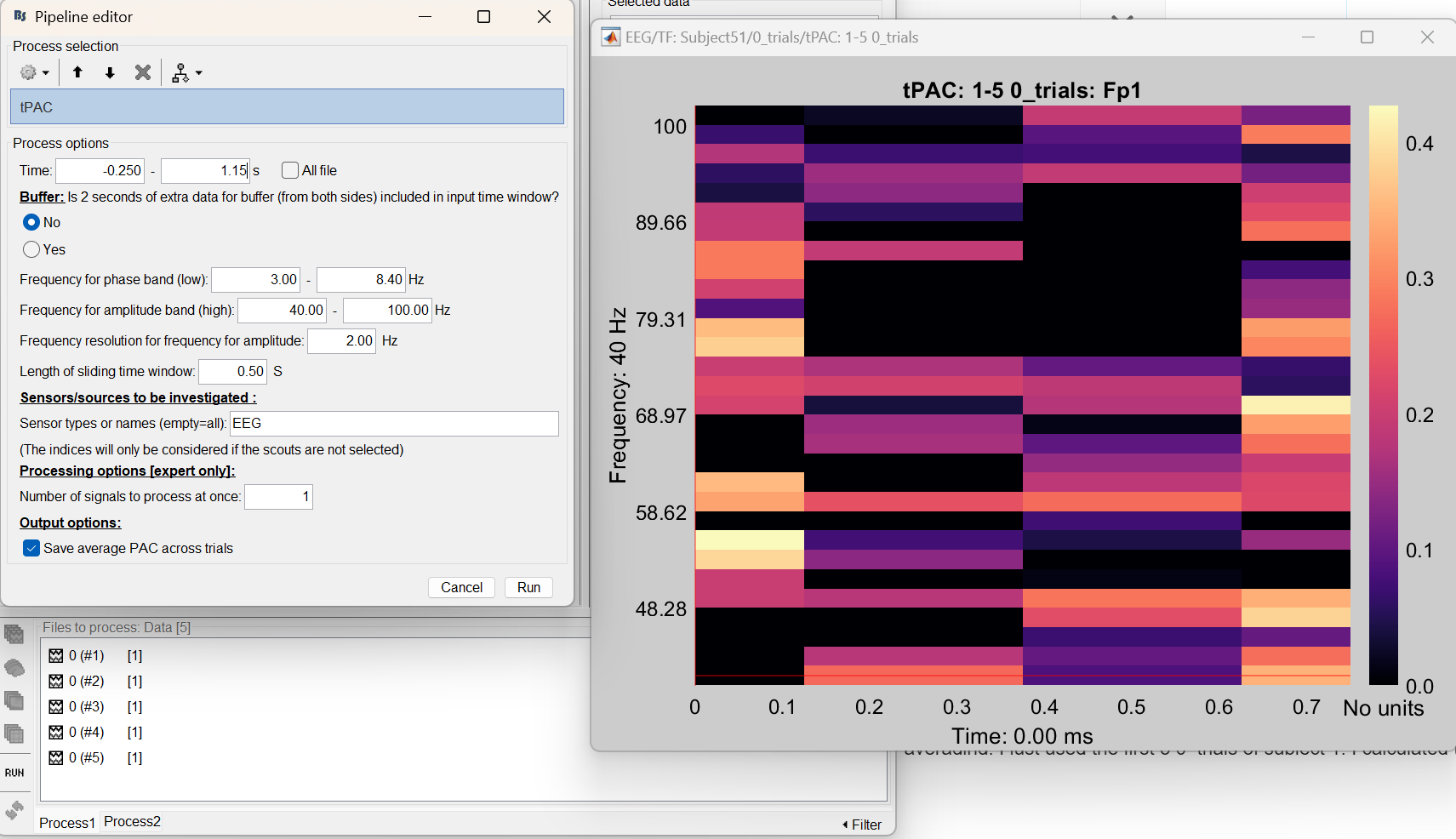
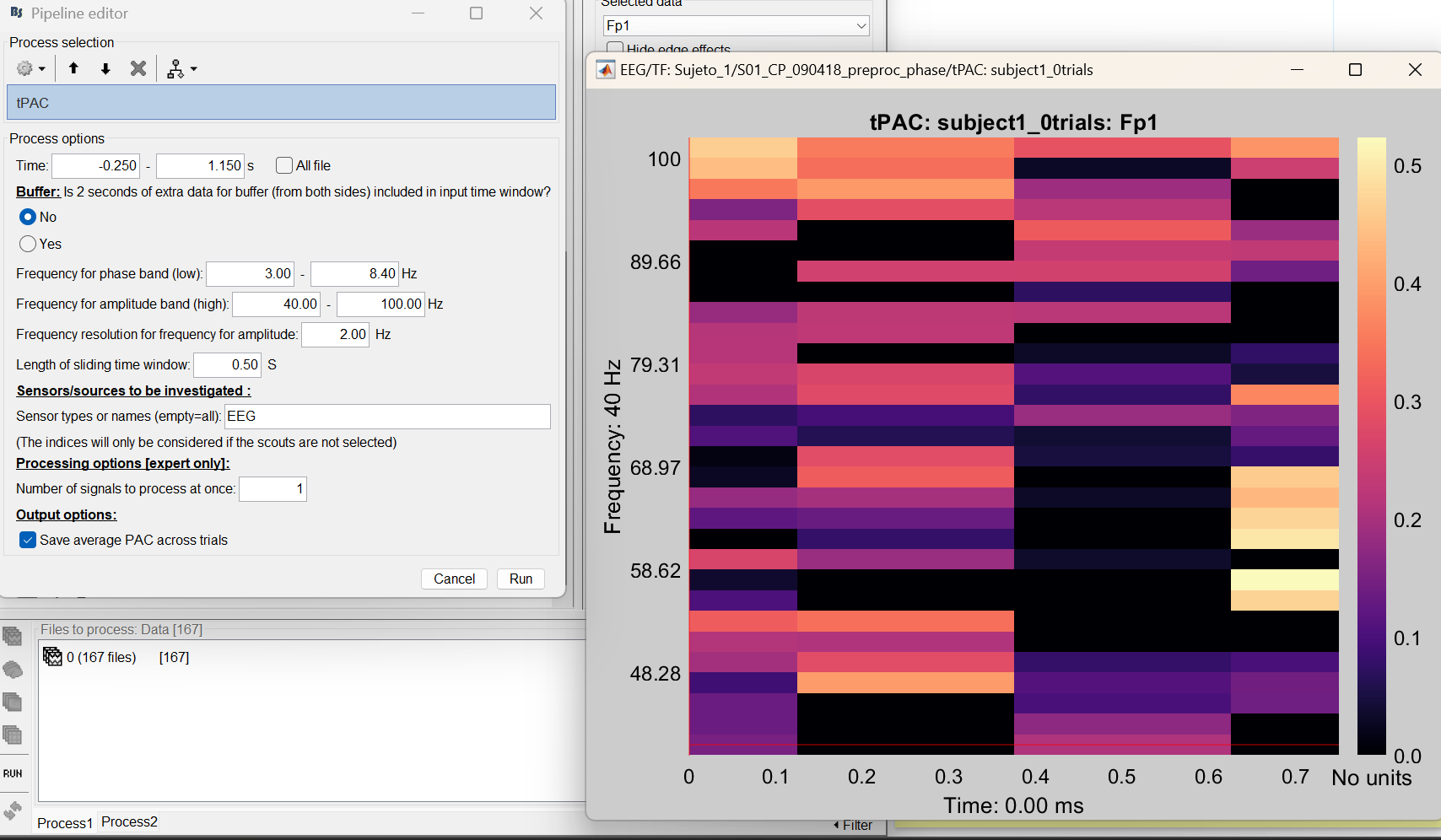
And regarding the last one, yes I am sure I am opening the right result. Actually I tried something different to see why the error is happening and maybe it is not a problem of subjects but only of averaging. I just used the first five 0_trials of subject 1 for calculating the tPAC, as i am showing here (both the input and the result).
Hence, I wonder whether the problem could be related to the fact that I am putting the files in separated lines in the box like this:
File (x1)
File (x1)
File (x1)
instead of all the files grouped:
File (x3)
However, I do not see any option through which I can group files to my choice.
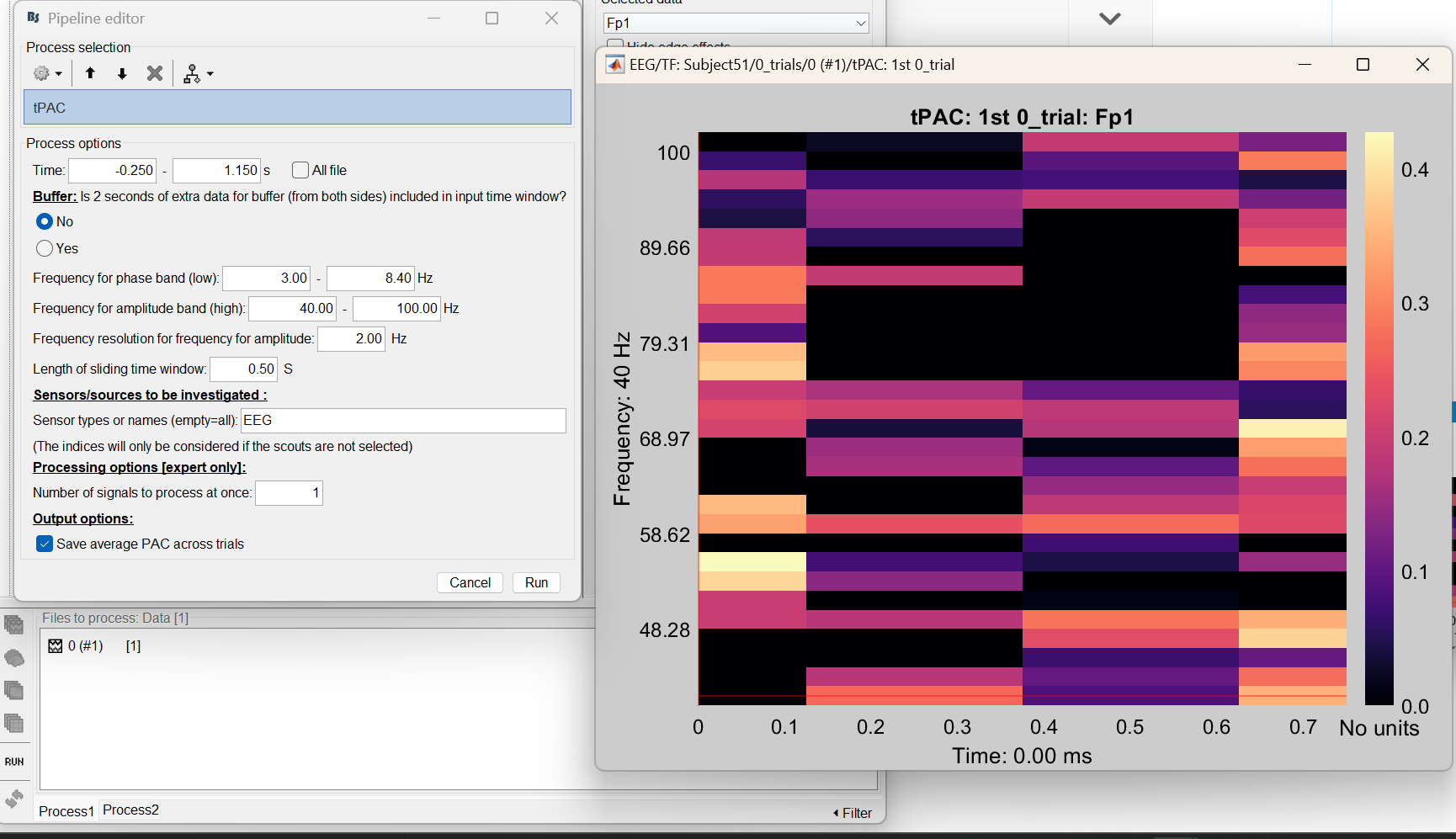
One last comment: I checked it and it is not a problem of putting the files in separated lines, as I am showing with the following two example analysis I performed:
The first image corresponds to only the first trial of all the ones I am analysing in the second image.
I found part of the issue. I'll have to discuss with the team if/how we want to correct this. At the very least, we'll have to improve the documentation.
The average option in the tpac process doesn't actually average the dynamic PAC values. It only saves each file's data in the same multi-dimensional arrays. But there's no way to view it in Brainstorm I think: it only shows the first "page" of the array, i.e. the first file that was processed. I guess it's meant to be exported to matlab and analyzed "manually". Again, I'll discuss with the team to see if we should instead actually do the average (I think so).
The error you show for process_pac_average seems to indicate your files did not have the same sizes. Either you had different frequency ranges, or maybe you tried averaging some that had the "average option" in tpac and some that didn't. The averaged ones have one extra dimension so that would cause this error.
Still, after trying to average single-files tpac, I get yet the same problem, as if it only keeps the first. Looking at the code, I find it's very bugged when using "by subject". It will take a few more days for us to fix and update. But using "everything" seems to work for my test examples.
So for right now, I'd suggest running tpac per file, then using pac average "everything", which you can of course also use to get a subject average (if you only input one subject's file in the process).
And I wanted to echo the comment on the tutorial about averaging these maps. Since each point picks a different nesting frequency (freq for phase, fp), the one that gives the max pac, you end up averaging different things here and care should be taken in interpreting the averaged results.
The PAC averaging process has been fixed. However, we're still discussing how to improve the tPAC process itself as none of the options would currently allow to do what I consider the ideal approach: averaging prior to collapsing across frequencies.