When trying to do time-frequency analyses on sources, it would be helpful to be able to average across participants (other functions in the “process” window might be useful too). Unfortunately, when trying to do this, BST throws an error saying that this is impossible because the file would be too big for Matlab to handle. My understanding is that 64-bit Matlab does not actually have a hard limit on the size of files it can process.
So my question is, is there any way to remove this hard-coded limitation is BrainStorm to allow for cases where one might have a system with sufficient resources to run processes on full-matrix time-frequency files? For example, I am running 64-bit Matlab on a Linux machine with 18 GB of RAM. It would be nice to at least be able to give it a try. I tried searching for the error message in the source files myself to try to remove this limit, but I couldn’t find it.
As an update to this posting, with a little help from my lab’s system administrator (Alex Waite, a great guy) I was able to find the file that throws the error when trying to run processes on time-frequency results in source space. So in the file brainstorm3/toolbox/gui/panel_nodelist.m, I commented out lines 567 through 578. After that I was able to average two t-f source-space files. Unfortunately, when I try to display the result I get the following errors:
** Error: Line 315: Attempt to reference field of non-structure array.
**
** Call stack:
** >tree_callbacks.m at 315
** >bst_call.m at 28
** >panel_protocols.m>CreatePanel/protocolTreeClicked_Callback at 106
**
** Error: Line 1407: Attempt to reference field of non-structure array.
**
** Call stack:
** >tree_callbacks.m at 1407
** >bst_call.m at 26
** >panel_protocols.m>CreatePanel/protocolTreeClicked_Callback at 135
**
Also, the output file is about half the size (64 MB) of the input files (128 MB each). So obviously something didn’t work.
I would greatly appreciate any help with getting this function to work.
At the present time, when you compute the time-frequency decomposition of a source matrix, it actually does the TF decomposition of the recordings, and then multiplies it by the inversion kernel at the desired vertices or time points. The full TF matrix is never fully computed.
It is theoretically possible to compute this full time frequency decomposition of a full source file. The size of the matrix would be, for a small file (let’s say 15000 vertices, 2000 time samples and 60 frequency bins):
15000 * 2000 * 60 * 8 / 1024^3 = 13.4Gb
For its manipulation, even if the code was extremely optimized, you would need at least 3 times the amount of memory, ie. about 40Gb of RAM. So it would not work, even on your 64bits linux system with 18Gb RAM.
Conclusion: this operation is not, and will never be, an option. The alternatives are the following:
[ul]
[li]Source reconstruction by frequency bands: Interesting option but would require some research and a lot of development. Will not be available in Brainstorm before 2012.
[/li][li]Time-frequency decomposition of some scouts time series. If you want a representation of the entire cortex, you can create a parcellation of the cortex in scouts with the menu New>Surface clustering in the Scout tab. Or use the Tzourio-Mazoyer atlas on Colin brain (load scout > scout_tzourio-mazoyer.mat). But you’d have to analyze the results by yourself, there are no display functions for this kind of data.
[/li][li]Do you time-frequency analysis at the sensor level only
[/li][/ul]
The numbers for the full matrix t-f file sizes in the tutorial are more like 1.3 Gb. But with the 13 Gb number you gave, I see now why it wouldn’t be practical. Thanks for the clarification!
Hi Francois,
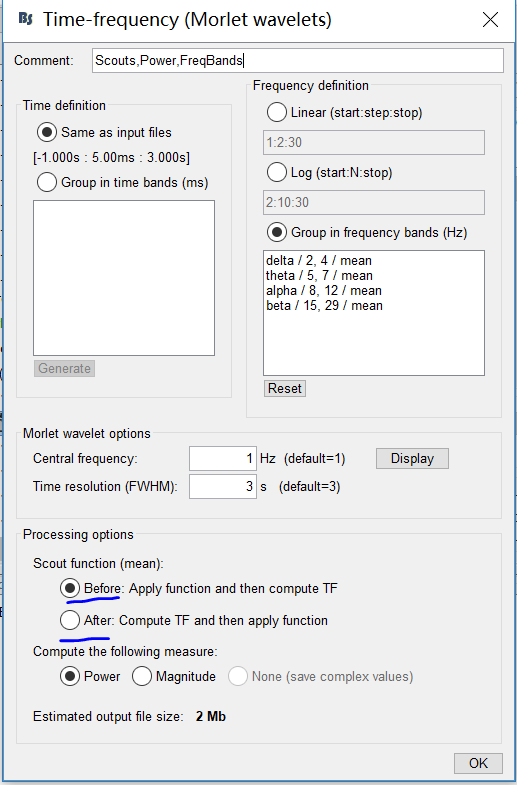
I'm doing time-frequency analysis and I wonder when to use the scout function is more appropriate, before or after?
Besides, I found if 'before' was chosen it would flip the sign of the sources automatically. I guess it means analyzing time-frequency using the absolute value, am I right? Will this make a difference?
Hello:
Choosing ‘before’ will compute the TF of the outcome of the scout functions applied to all sources in the scout region. Practically speaking, if the scout function is ‘mean’, the average time series is extracted across the scout time series. Because of sign ambiguities due to source localization on the cortex, the sign of some of the time series is flipped to align better with the trend observed across the scout. It is to augment sensitivity of the averaging statistic. Then the TF is computed: it is not that of the rectified (absolute values) time series, so the power fluctuations observed in different frequency bands reflect that of oscillatory neurophysiological activity, in principle.
Choosing ‘after’ computes the TF of all scout time series independently, then compute the mean (scout function): this method is preferred, because more sensitive, but is more greedy in terms of computation.