Hi François!
I post some of the issues we have been discussing here, in case they may help other people:
1- Running Brainstorm on a cluster:
From Macos/Linux:
brainstorm3.command <MATLABROOT> <script.m> <parameters>
It's important to include this matlab root, which can also be the Matlab RunTime (in case you want to run it without Matlab license). This info is now included in the tutorial. Thanks!
.
2- To avoid being asked for “brainstorm_db” every time add: local
Example:
brainstorm3.command /usr/local/MATLAB/MATLAB_Runtime/v98 main.m local
This will use a local_db automatically created at: $HOME/.brainstorm/local_db
.
3- With all these, the following lines in the tutorial example script are not longer needed:
% Set up the Brainstorm files
pathStr = '/home/user/brainstorm3/';
addpath(genpath(pathStr));
BrainstormDbDir = '/home/user/brainstorm_db';
% Start Brainstorm
if ~brainstorm('status')
brainstorm server
end
Since brainstorm is already started with the command call (maybe worth commenting it in the tutorial example)
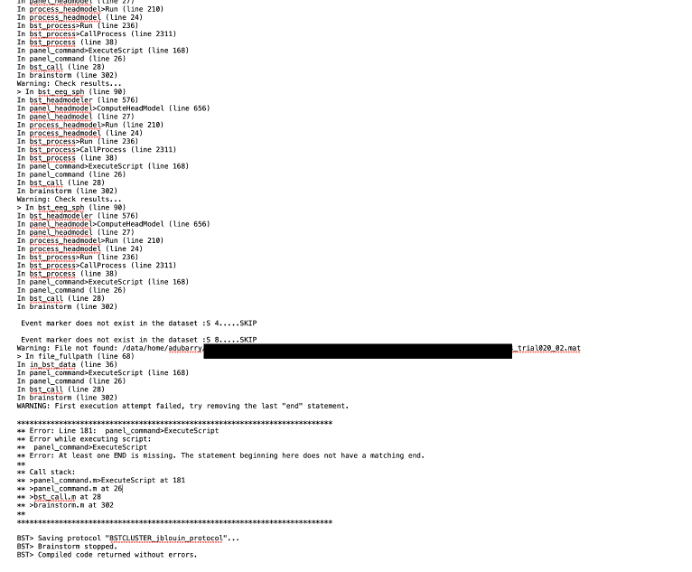
With this way of using brainstorm we have to be very careful of the projects created in the database.
If brainstorm gives an error, and the ProtocolX has been created but not properly registered in Brainstorm. Then, it won’t allow you to create a new one with same name or delete it using brainstorm functions:
gui_brainstorm('DeleteProtocol', ProtocolName); or
gui_brainstorm('CreateProtocol', ProtocolName, 0, 1);
A few more questions:
** Can we change the local_db location [automatically created at: $HOME/.brainstorm/local_db]??
If we create a container with brainstom3.command+matlab-runtime, and multiple users are running it, their databases may collide, therefore, I think it would be useful if their brainstorm_db folder could be specifically changed to be in their home directory. With the local option, it seems this is not possible. And without using the local option, it keeps asking on the command line about the brainstorm_db folder location, which can’t be entered while running automated scripts.
** Where is the information related to Brainstorm registered protocols stored??
Thanks a lot!
(Still need to try the new container)