I am working on scripting an analysis which was initially performed manually from the Brainstorm GUI. I am working from the database that was created by a user from the GUI.
I am facing a reproducibility issue. The main first steps of the analysis are :
Import
Epoch
Baseline removal
Resample
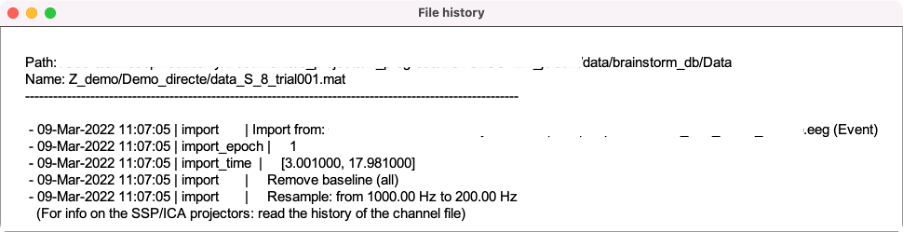
Below the history of one the "inital" files (from the database that I was given to reproduce)
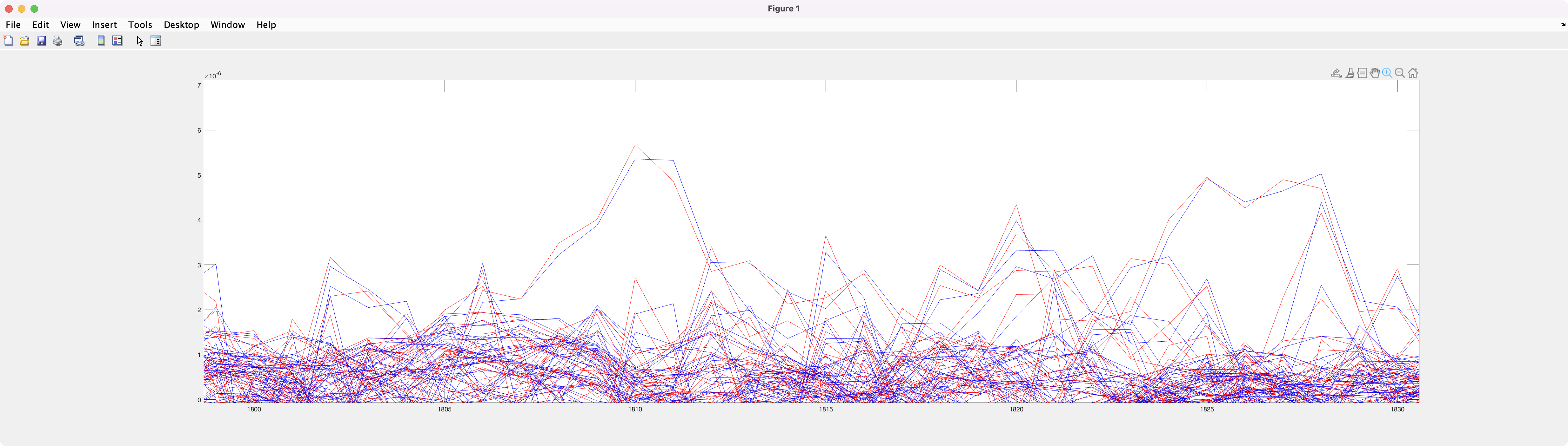
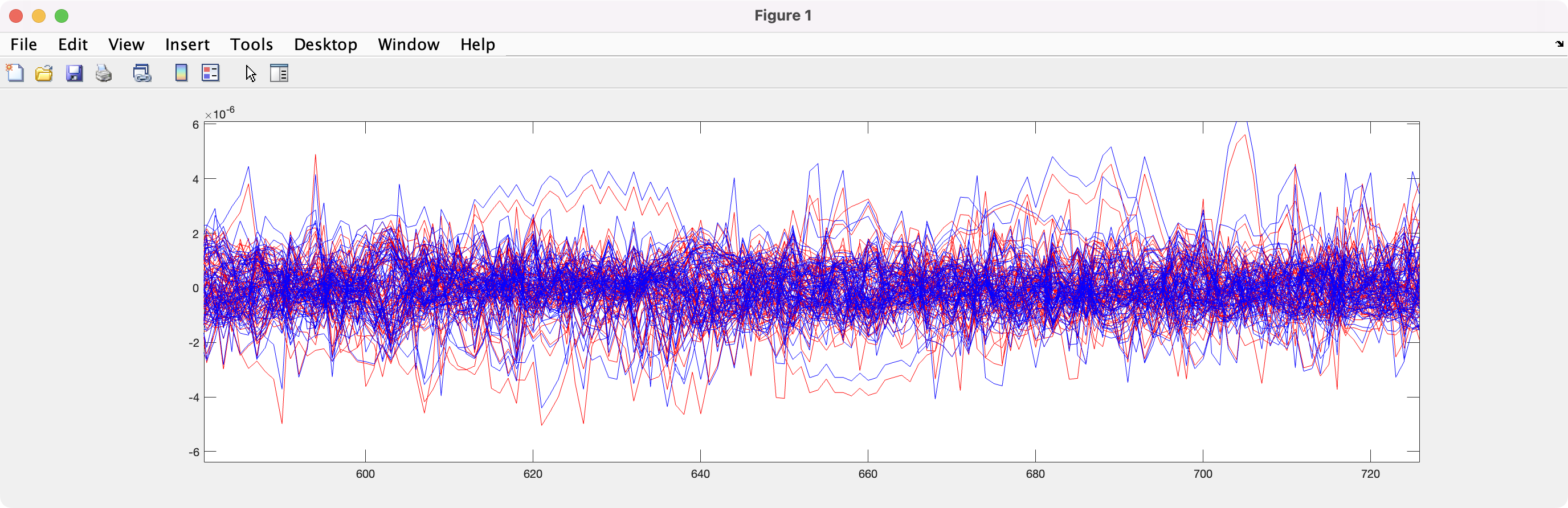
In order to quickly compare the two datasets I computed an average across trials. When plotting them on a same graph with distinct colors (red, blue) I see slight differences.
From the history, I suspect that the version of brainstorm which was used for the first analysis is not the same as the second one... does this explain the differences in the averages?
This however indicates that the processing script was not generated using the most optimal option. When generating a pipeline that does successfully import + DC correction + resample: the script generator optimizes the pipeline and adds option entries resample and baseline to the call to the import process.
The epochs are then fully processed and then saved on the drive, instead of being saved by the import process, then read and saved by process_baseline, then read and saved by process_resample.
And you fall back exactly on case #1.
Case #2 is coming from a script that should be fixed.
Example:
The differences you observe in the two graphs could be due to many things. In the first place, the import times for the epoch are not the same. There is a 1 sample shift between the two.
If you can reproduce the same difference between the two options with: a) the same version of Brainstorm and b) the fixed epoch time, there is probably something that should be fixed somewhere.
Let me know how to reproduce and I'll investigate.
Thank you for your response. I now fixed the script such that
It now computes import + DC correction + resample all at once (with adding the option entries resample and baseline to the call). Thank you for suggesting the improvement.
The history now shows :
If you know the date, maybe from the protocol folder creation, you can pull any past version from GitHub.
In GitHub, navigate to an older commit, then download the corresponding data tree (green button from the github website).
From the difference you observe here, I guess there were maybe differences in the filters or in the ICA.
Note that there is a random initialization in runica, and the result is not deterministic, unless you initialize the Matlab random generator to a fixed seed at the beginning of your script.