Often times we populate a database and then we want to access files for subsequent analyses. I can use the process:
File->select files->recordings
to select files with recordings based on subject name, condition name, and filename contains tag. However I cannot select recordings by trial group. I cannot use the tag because my event codes are 1,2,3,... so selecting a tag 1 will include 10, etc.
For example, the process 'Average' allows averaging trials by subject, folder, and trial group. Is it possible to enhance the file select process (recordings but also sources, time-freq etc) to enable selection of trial groups?
This is something you should be able to do with the new search tools that @MartinC introduced recently.
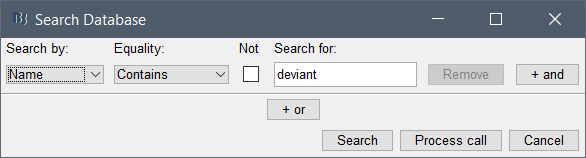
Prototype your search string with the search GUI, then use it as a process after the process that selects the files in the database. With a combination of a selection process followed by a search process, you should be able to grab exactly the files you need from the database.
Are there cases you can't handle correctly?
I guess you are right, you can combine the file selection process (File->select files->recordings) with Martin's new search function to accomplish practically everything. Indeed it works.
I implemented this and here are some thoughts for possible improvements:
File selection can be a slow process. For a subject with 2300 trials (rather typical number) the File->select files->recordings process took 23 seconds to identify all files, and then another 1.3 seconds for Martin's function to select files with '1' in their name.
If instead I organize my trials by conditions and not trial groups (select 'create a separate folder for each event type' when importing the trials), the File->select files->recordings process is way faster when restricted to a given condition. It took only 0.5 seconds to find the trials of condition '1'. Thus, there is some drawback in organizing trials in trial groups instead of conditions. I am curious why it takes so long for the 'process_select_files_data' to find all files, probably some Java or interface limitations?
It would be useful to be able to 'generate a process call' from Martin's search tools without actually running the search. In a complete database of say 20 subjects with thousands of trials each it often takes too long to search just in order to generate the process call.
File selection can be a slow process. For a subject with 2300 trials (rather typical number) the File->select files->recordings process took 23 seconds to identify all files, and then another 1.3 seconds for Martin's function to select files with ' 1 ' in their name.
This is insanely long, we can improve this I guess...
Do you have removed any tag search from the selection process?
Could you run the Matlab profiler on this search? Write your file selection as a script, add "profile viewer" at the beginning of the script and "profile viewer" at the end. Then please post a screen capture showing what is taking all this time.
Another solution would be to improve Martin's search process so that it also does the initial file selection (it may require an additional option to select the file type?) @MartinC do you want to work on this?
It would be useful to be able to 'generate a process call' from Martin's search tools without actually running the search. In a complete database of say 20 subjects with thousands of trials each it often takes too long to search just in order to generate the process call.
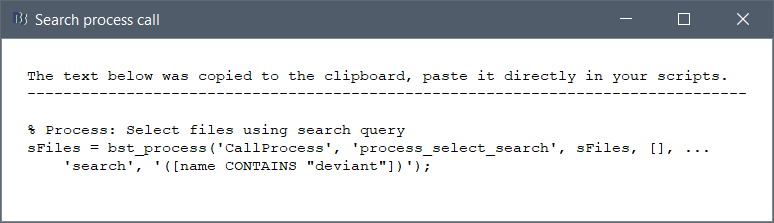
It could be something like this (clicking on "Process call" would open directly the figure with the script ):
It could be something like this (clicking on "Process call" would open directly the figure with the script ): @MartinC Do you see any easy way to do this?
Yes, that's indeed quite easy. I've implemented this in the following commit: Database search: option to create script without applying search · brainstorm-tools/brainstorm3@1c53600 · GitHub
I added a smaller button on the bottom left to generate pipeline scripts right away rather than applying the search first. I think it's more of an advance use and I liked the right side buttons to be dead simple. If you disagree let me know and I can make it a bit more obvious.
Another solution would be to improve Martin's search process so that it also does the initial file selection (it may require an additional option to select the file type?) @MartinC do you want to work on this?
Sorry, I don't think I understand what you mean. We can already search by file types using my search queries. I feel like combining the "Select files: recordings" & "Select files: search query" processes makes sense in this use case, otherwise you need to duplicate all parameters of the first process to my new one to make it work in a single call. I think profiling the "Select files: recordings" process is the way to go to see if it could be optimized. I can help on that front.
It would be nice if this process could directly select the files from the database, in case there are no inputs. I think it's counter-intuitive to have to "select files" and then "search files".
Your search box lets us do everything the selection process does, except for the actual initial selection of all the files from the database. Could you add something like this?
No need to add any option, because indeed it is already possible to filter by file type, but then you should add an error when multiple file types are returned by the same search, indicated that the user should probably add a filter by file type to the search.
Thanks François. So if I understand correctly, the same process would have two use cases:
With files as input -> return a subset of these files that pass the search filter (as it works right now)
With no files as input -> return all files in the current protocol that pass the search filter
And we don't need to add the subject name or condition name options like the "Select files: recordings" processes since users can do the equivalent search query using "search by: parent name"?
All your above comments sound great! Indeed the process process_select_search will be much more useful if you can select files from an empty input (as long as it is fast!).
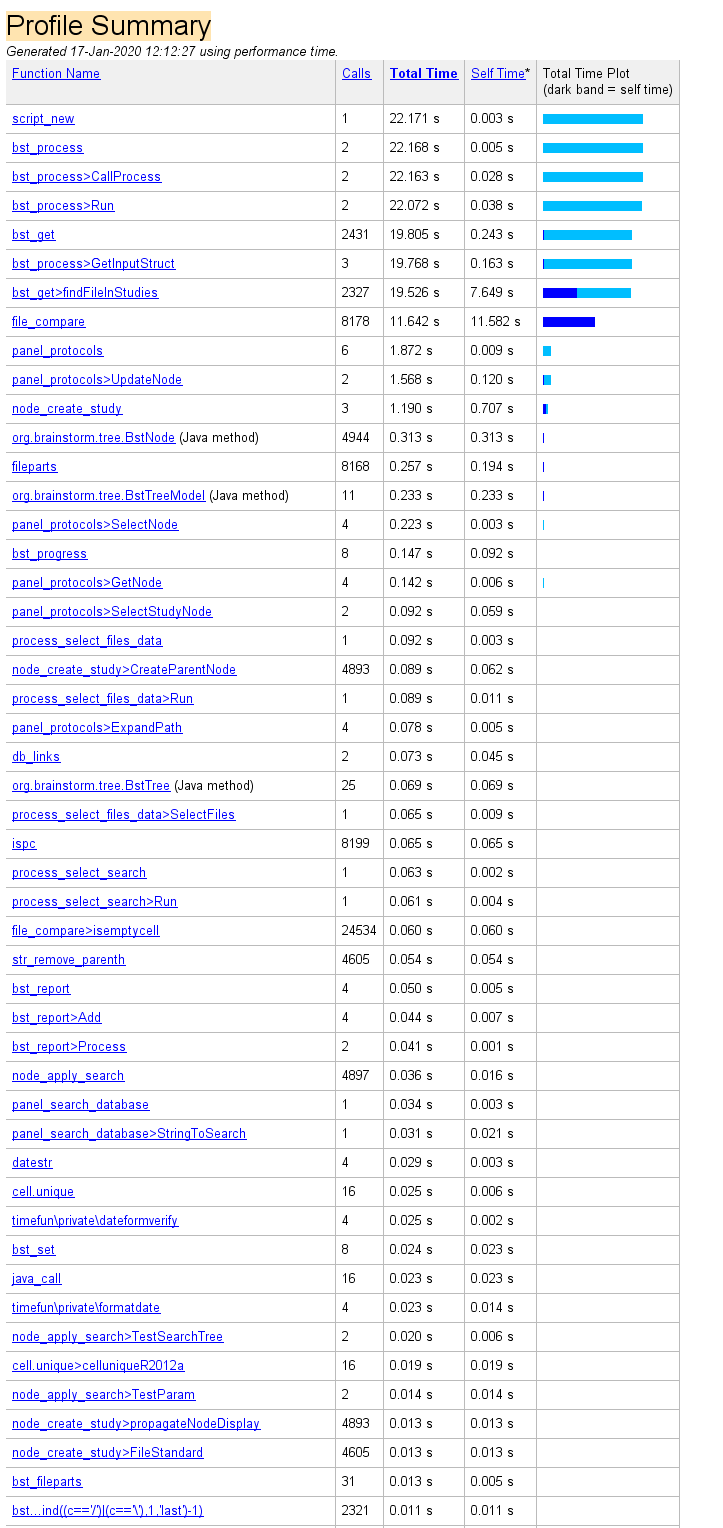
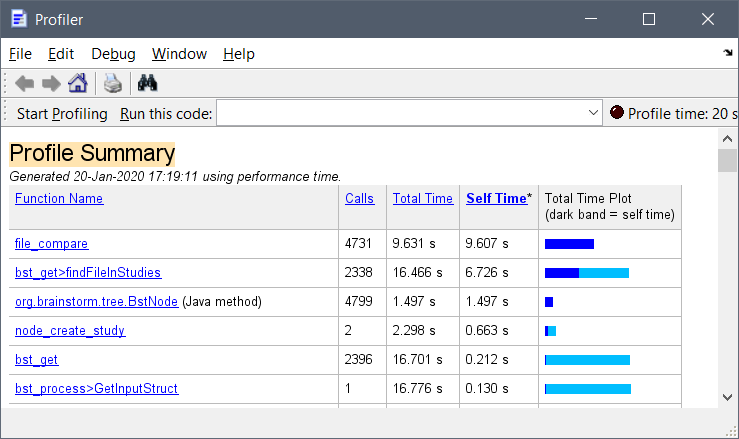
I run the process_select_files_data to select all trials in a subject that has 2284 files organized in (a) 144 conditions, or (b) 144 trial groups. This time it took (a) 5.6 seconds and (b) 15.7 seconds. Below is the profiler screenshot for case b:
To find which studies to redraw in the database. This could be skipped here since this is a read-only process, the database was not modified.
To update the report, but I don't think the structure is required for that, the list of files would be enough.
How about we add a new "read-only" field to certain processes and when it is set, we skip this step in bst_process? I am fairly confident this would cut most of the overhead here.
Or there might be an even better solution here, let me know.
Thanks for investigating this issue.
Removing the call to GetInputStruct makes the selection call faster, but reports the problem on the following call, which will need to call it in order to obtain the subject/study indices...
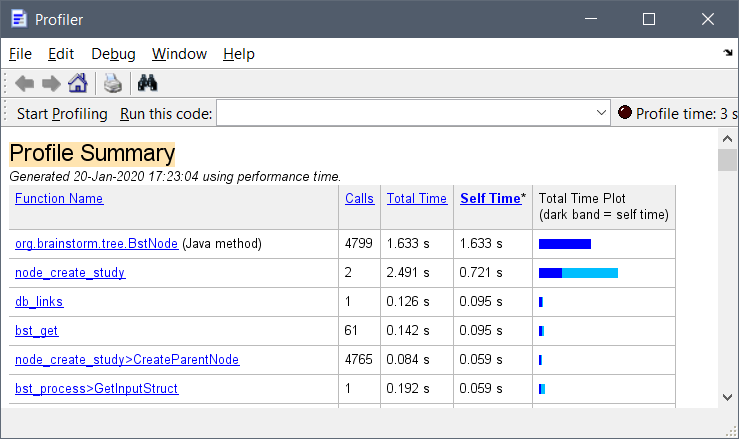
I run the process_select_files_data again to select all trials in the subject that has 2284 files organized in (a) 144 conditions, or (b) 144 trial groups. While (a) did not improve as it still takes ~5 seconds, (b) improved dramatically from 15.7 seconds to only 0.5 seconds!
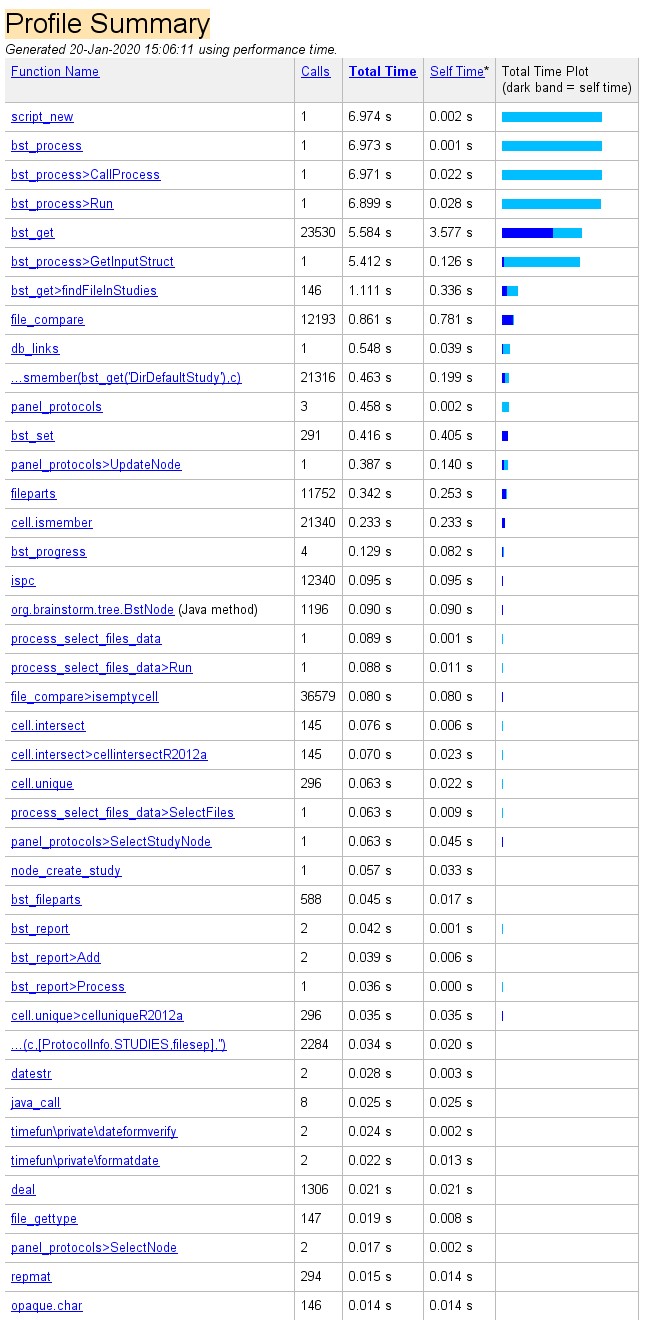
In case it helps, here the profiler summary for (a):