Hello, please I am computing wPLI on 28 epochs. Do I choose timeres none or full(requires epochs)? What is the difference?
Thank you dear expert.
Hello, please I am computing wPLI on 28 epochs. Do I choose timeres none or full(requires epochs)? What is the difference?
Thank you dear expert.
It depends on what is your research question.
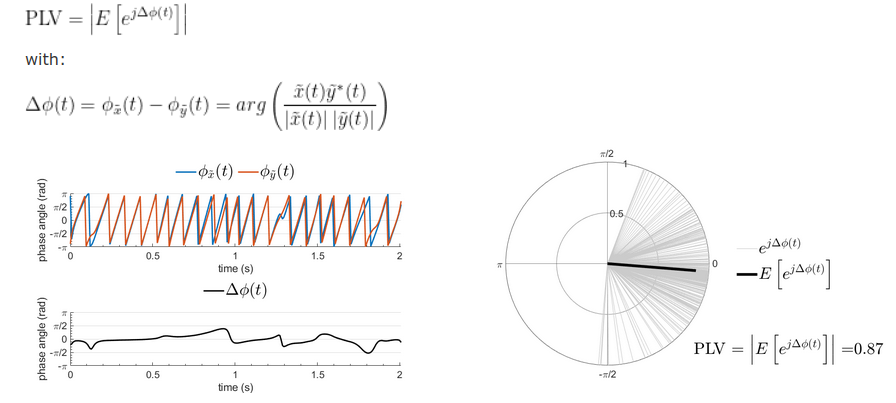
This refers to the data (x(t) and y(t)) that will be used to compute the PLI metrics.
Consider these cases:
Time resolution: None, Output option Save for each file
For each input file, One PLI value is computed for each combination of EEG sensors, and one all the time samples in the file are used. Thus there is 1 PLI value per file per EEG sensor combination.
Time resolution: Windowed, Output option Save for each file
For each input file, data is divided in N time windows, and for each time window, a PLI value is computed for each combination of EEG sensors, using only the samples in that time window. Thus there are N PLI values per file per EEG sensor combination.
Time resolution: Full (requires epochs), Output option Across combined files/epochs
For time sample, a PLI value is computed for each combination of EEG sensors. However, instead of using time samples, PLI is computed using the same time samples from all the input epochs. Thus there is a PLI value for each time sample, per file per EEG sensor combination, but it requires epoch/trials, otherwise, PLI would be always equal to 1.
In the case of None and Windowed if the output is set to across combined files/epochs, time samples (either in the entire file or time window) across trials will be used to compute the PLI.
So if I undestand it right, if I am only interested in one matrix per epoch, I should use none.
One more question please, how do I tell BS to skip bad epochs for connectivity computing. For PSD it does so automatically, but it computes connectivity anyway.
Thank yoy very much.
For PSD, windows with bad segments are avoided when compute PSD on raw continuous files. When the epochs are imported, the entire epoch is labelled as bad if it has a bad segment.
Then, connectivity metrics are only available for imported epoch, in this sense, they are computed only on good data. So there is no need to ignore bad epochs, since they are not even considered.
The thing is, I imported epochs and computed PSD earlier and now I've came back to compute connectivity measures and export them to futher analysis. How you can see, it is computed even for bad epochs and I dont want it, I just want to skip the bad epochs.
... how did you get to this point?
yes I am doing everything with scripts. My analysis has 2 objectives: first evaluate PSD changes and second to search for biomarkers, I chose connectivity. So in the beginning I did the classic preprocessing, incdluding tagging bad segments and electrodes. Then I made a script for epoch import and I computed PSD on each of them. Then later I came back and on those same epochs I had already imported, I computed connectivity measures.
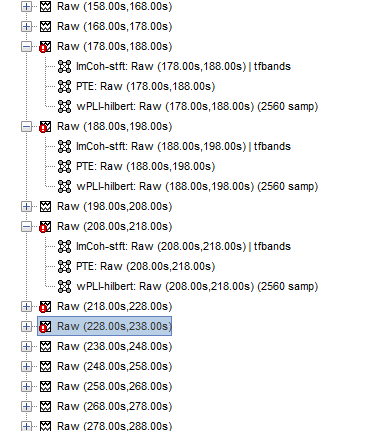
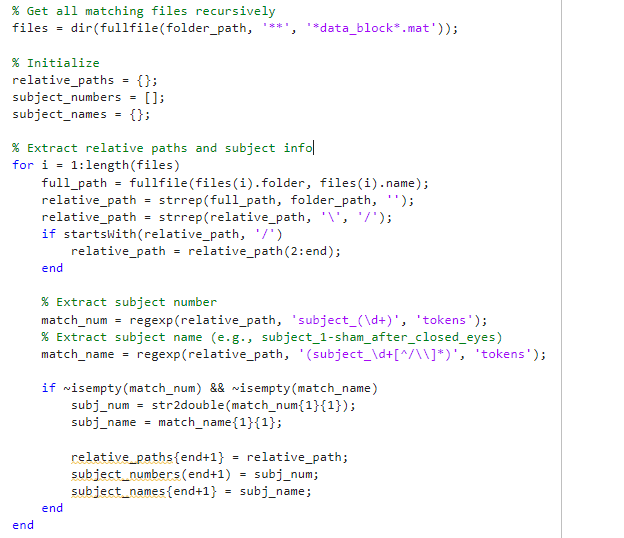
The first thing I do in my script for connectivity analysis is that I find all data_block file in current protocol like this:
I guess problem is in this, however I supposed that in .mat files of data_blocks is some kind of information for BS that it contains bad segment, so it will be skipped in connectivity analysis. My assumption is present because for example I used the same chunk of script for selecting all data_block files when I realized I have to recompute PSD with different options and it successfully skipped the bad epochs. It does not work for connectivity though, it seems.
EDIT: sorry when I recomputed PSD, I imported all epochs again. I did not use this chunk of script for selecting data_block.mat. So I only used this chunk for connectivity, for the first time.
So I have to import epochs again right?
The problem relies in the script.
You are getting all the files data_block.mat regardless if they are good or bad.
(If you run PSD on those files, you will also get a PSD for the bad trials)
The information of a bad/trial is saved in the Study file
Check the section List of bad trials in this link:
Instead of manually going through the files in the HDD, A better way is to use Brainstorm processes to get files:
which give this script:
% Process: Select data files in: Subject01/condition_name
sFiles = bst_process('CallProcess', 'process_select_files_data', [], [], ...
'subjectname', 'subject_name', ...
'condition', 'condition_name', ...
'tag', '', ...
'includebad', 0, ...
'includeintra', 0, ...
'includecommon', 0, ...
'outprocesstab', 'no'); % No
Then you can be sure that sFiles are your recordings for Subject Subject01, for condition condition_name, and bad epochs are not included.
Using the process, will save you time to manually handle paths.
Moreover, there are functions such as file_fullpath() and file_short() to obtain the full path and relative path for files.
Check this tutorial for tips and guidelines to write scripts:
https://neuroimage.usc.edu/brainstorm/Tutorials/Scripting
Thank you, I somehow missed option of selecting files with BS functions. I am already using it.
However next question came to my mind. Please, how can I pass the information that epoch is bad from BS to Fieldtrip? The reason is that I want to also compute phase slope index on my epochs and that option is in Fieldtrip only as far as I know.
This is the answer you are looking for ![]()
In short, that info is in the brainstormstudy.mat file.
Ahh thank you, I see you answered already in the last message, sorry for that.