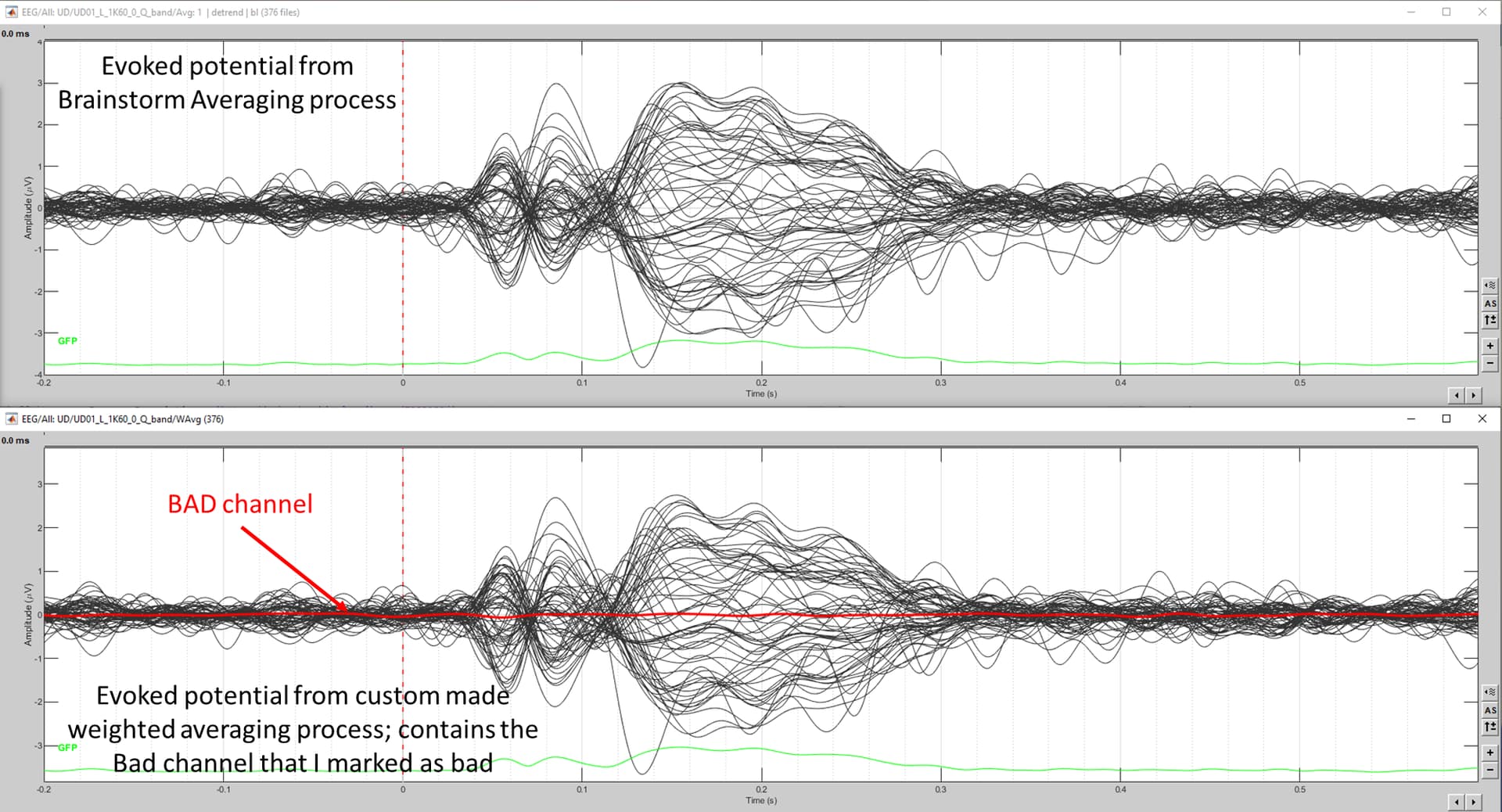
The bottom file is a custom Brainstorm process that I made for my auditory evoked potential study. It takes in X number of epochs and runs weighted averaging (based on residual noise), calculates classic and weighted residual noise and noise per epoch. The outcome is that it produces four recording files for each calculated outcome. Upon inspecting the outcomes from this process I realised that the channels that I marked as "bad" are no longer considered as "bad" after I run the epochs through this custom process. For example, the below shows the effects of using my custom process. The top is using the Brainstorm's averaging process which excluded the "bad" channel that I marked previously. However, the bottom (my custom process) did not exclude the "bad" channel and is appearing as a flat line.
Therefore, it seems like my custom process is not reading which channels are bad and good. To amend the code I considered the "process_average.m" Brainstorm process but could not find what I was looking for regarding something along the lines of "read channel data" or "read channelflag" etc. How can I amend the code so that it reads which channels are good and bad, incorporates this in the computation and in the file contents reflects the same good and bad channels?
Edit: I realised that the file contents do not reflect which channels are good and bad as this is not coded properly. As you can see below (the code is an excerpt from the process uploaded above) the ChannelFlag is just a list of "ones" according to the number of channels. Therefore I also need to amend this so that it reflects which channels are bad and good.
DataMat.ChannelFlag = ones(epochSize(1), 1); % List of good/bad channels (1=good, -1=bad)
Yes, this is what is happening. In the shared script, the reading loop (L62-L76) does not consider the ChannelFlag field in the loaded DataMat for each loaded file.
Be mindful that 1 means good channel and -1 is bad channel
First you should get the field ChannelFlag in your reading loop. Then there are at least two approaches:
Discard from the final result channels that are bad in one or more epochs. Same as as keep only channels that are good for Epoch1 AND Epoch2, AND, ... EpochN. To do so, the ChannelFlag field in the final DataMat can computed in the reading loop, and keep only channels that are good for every Epoch.
FinalChannelFlag = ones(epochSize(1), 1); % Start with all channels as good
% Reading loop
for ...
goodChannels = (DataMat.ChannelFlag == 1);
FinalChannelFlag = and(FinalChannelFlag, goodChannels);
end
FinalChannelFlag = double(FinalChannelFlag;)
FinalChannelFlag(FinalChannelFlag == 0) = -1;
Compute the final result channels considering bad channels for specific epochs. In this option, the epoch weight (for the weighted average) needs to be weighted again considering how many times (in how many epochs) a channel was good.
Thank you for the reply Raymundo; I have three follow-up questions if that's okay.
You mentioned that the script does not consider the ChannelFlag field in the loaded DataMat for each file. So then how can I amend the code to enable this? I imagine that I would need to use "mat.ChannelFlag" in the code somehow.
For the first approach, it looks like this is suggesting to first compute which channels are good and bad for all loaded files before the actual calculations take place, is that correct? Could you provide further clarification?
Apologies but I don't understand what you mean by the second approach. Is this saying that after all the calculations have taken place to re-calculate (a new) epoch weighting based on the number of epochs a channel was good and apply that weighting to the already calculated final calculation? Effectively, approach one is to consider the ChannelFlag before the main calculations and approach two is to consider the ChannelFlag after the main calculations - correct?
Yes, in the snippet of code that I added above, the idea is to read use the channel flag of each epoch to generate the final channel flag. The Reading loop in the snippet is the reading loop in your script.
There is no need to do it before. Since channels are processed independently (in your script), it is not necessary to remove them before doing the computations. It is only needed to generate the final channelFlag is updated with each Epoch, and this channelFlag will ensure that those bad channels are not shown.
This would be the case you want to still compute the metrics for a channels that is bad in one epoch.
Not really. Approach1 metrics from bad channels are ignored from the results. In approach 2: the computation of the metrics needs to take into account the number of Epoch in which each channel was good. Let's use this situation as example: All channels are good for all Epochs, except that for one Epoch channel1 is bad.
Approach 1: Metrics are computed for all channels, but the final channel flag indicates that channel1 is bad, because it was bad one at least one Epoch, so its metrics will not be shown.
Approach 2: It is necessary to keep track of the Epoch and the Good channels, so the metrics per channel must be computed using only the number of good channels*. So the result metrics for channel1 will be computed using only N-1 Epochs. At the end, the final ChannelFlag will indicate that all channels are good, as their metrics were computed only with Epochs where those channels were good.
@Raymundo.Cassani thanks for the explanations after considering my options I've decided to do the following. Hope you can let me know your thoughts about anything that seems wrong or odd with the below.
All the individual epochs in a folder were imported from the same preprocessed link to raw files therefore ALL the epochs contain the SAME list of bad/good channels. Therefore all I needed to do was include the lines "ChannelFlag = DataMat.ChannelFlag" and "DataMat.ChannelFlag = ChannelFlag" in the code below. This will read the DataMat.ChannelFlag from the first file and apply the ChannelFlag when saving the results. As all the epochs contain the same list of good/bad channels there is no need to find out the list of bad/good channels for every single epoch. And as all the channels are weighted independently (as you rightfully pointed out) there is no need to find out the list of bad/good channels for every single epoch.
I think this is the simplest solution to my original question. What are your thoughts on this? Will the DataMat.ChannelFlag data that I've included be incorporated in subsequent processes? Do you see this having potential issues immediately and in more advanced processing steps such as source analysis? (i.e. any potential flow-down errors that might result from this?)
% ===== LOAD THE DATA =====
% Read the first file in the list, to initialize the loop
DataMat = in_bst(sInputs(1).FileName, [], 0);
%%%%% ADDITION %%%%%%
ChannelFlag = DataMat.ChannelFlag;
%%%%%%%%%%%%%%%%%
epochSize = size(DataMat.F);
Time = DataMat.Time;
% Initialize the load matrix: [Nchannels x Ntime x Nepochs]
AllMat = zeros(epochSize(1), epochSize(2), length(sInputs));
% Reading all the input files in a big matrix
for i = 1:length(sInputs)
% Read the file #i
DataMat = in_bst(sInputs(i).FileName, [], 0);
% Check the dimensions of the recordings matrix in this file
if ~isequal(size(DataMat.F), epochSize)
% Add an error message to the report
bst_report('Error', sProcess, sInputs, 'One file has a different number of channels or a different number of time samples.');
% Stop the process
return;
end
% Add the current file in the big load matrix
AllMat(:,:,i) = DataMat.F;
end
AND
% ===== SAVE THE RESULTS =====
% Get the output study (pick the one from the first file)
iStudy = sInputs(1).iStudy;
% Create a new data file structure
DataMat = db_template('datamat');
DataMat.F = AllMat;
DataMat.Comment = sprintf('WAvg (%d)', length(sInputs)); % Names the output file as 'WAvg' with the number of epochs used to generate the file.
%%%%% ADDITION %%%%%%
DataMat.ChannelFlag = ChannelFlag; % List of good/bad channels (1=good, -1=bad)
%%%%%%%%%%%%%%%%%
DataMat.Time = Time;
DataMat.DataType = 'recordings';
DataMat.nAvg = length(sInputs); % Number of epochs that were averaged to get this file
% Create a default output filename
OutputFiles{1} = bst_process('GetNewFilename', fileparts(sInputs(1).FileName), 'data_WAvg');
% Save on disk
save(OutputFiles{1}, '-struct', 'DataMat');
% Register in database
db_add_data(iStudy, OutputFiles{1}, DataMat);
This sound right for the nature of your dataset, and the code looks right.
You may want to generate the final ChannelFlag as aggregate of the all the input ChannelFlags. It will not change the result in the current data, but it may save you headaches when re using the process with other data where channel flags may not be uniform. See the snippet provided above.