I'm currently rotating in an MEG lab and am trying to get a better understanding of Granger Causality. Conceptually it makes sense, but I'm still struggling with implementation in Brainstorm.
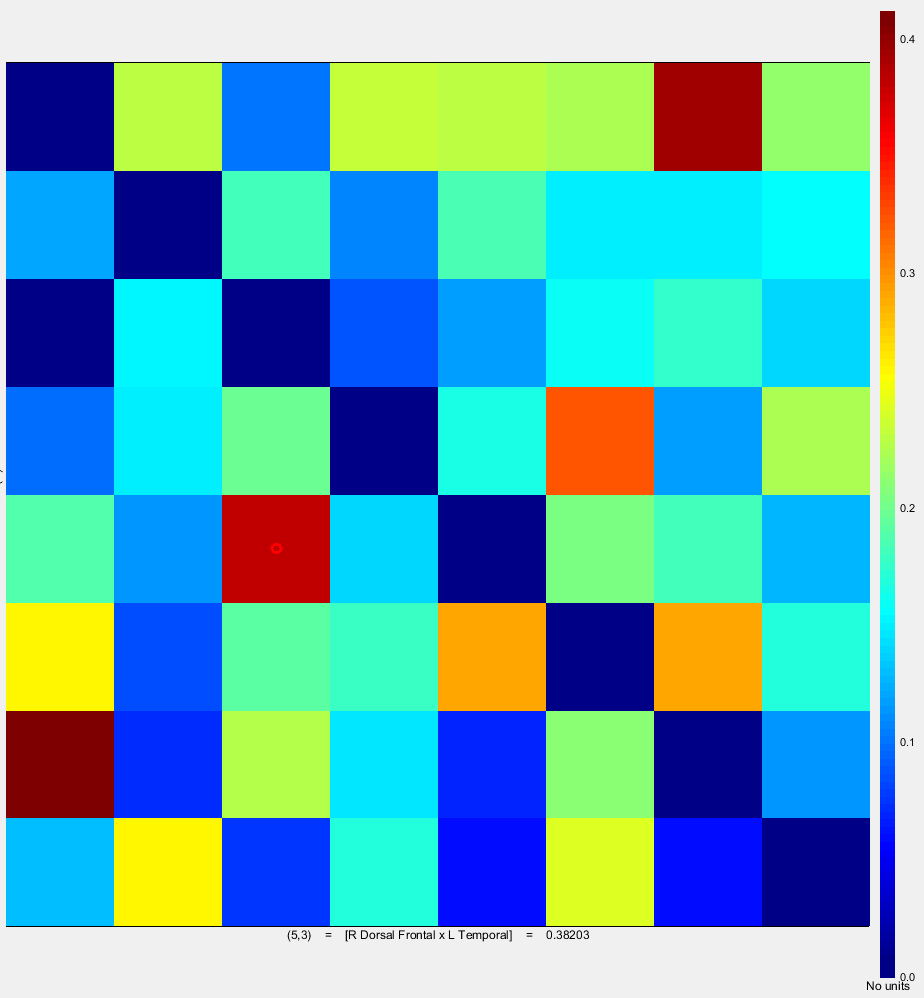
After pre-processing I made scouts that defined some of my ROIs. I then extracted time series for my scouts (as one file), and used the resulting file as input for Granger analysis. The output file I get is an NxN heatmap where N is the number of scouts I wanted to look at. So I now have interactions between all of the ROIs, but the numbers given to each scout pair are unlabeled. Is the way I went about this appropriate? And if so, how should I interpret the heat map? Do the numbers represent p-values?
The best way to run this is to skip the extraction of the scouts time series: use directly the source files in input of the process Granger NxN.
Then select the option “Use scouts” and select the scouts your need.
The option “Scout function: after” would evaluate first all the interactions between all the pairs of vertices in your N scouts, and then group the values by scouts.
When you display the connectivity graph by double-clicking on it, if you click on the image, you get the labels of the [row x column] at the bottom (as shown on your screen capture). You can also use the “Display graph” option in the popup menu of the file.
Note that those maps are not statistically thresholded. The values returned by the Granger causality function are unitless and their values are difficult to interpret or compare. The tools available for assessing what is significant in those graphs will be developed during the next two years.
I know many people study more the asymmetry of those values (A>B) rather than the values themselves. But for now, I’m sorry I don’t have any better guidelines to give you on how to process those values.
Coherence is probably an easier metric to work with, and much faster to estimate.
(there are no statistics for coherence values either, you’d still have to do the thresholding yourself).
When I look at coherence across multiple scouts, is asymmetry of the output values still going to be my main metric? Are there any resources available that you would recommend for appropriate threshold/statistics applications?
Coherence is a symmetric measure (A>B = B>A) and its values are normalized between 0 and 1. They are easier to interpret directly than the Granger causality values.
All the connectivity functions work exactly in the same way. The different output you get is not due to the metric or the way you defined your ROIs but to the options you selected for the Granger/coherence processes.
The image you posted shows what you get if you select “Scout function = All”.
I want to perform Granger causality analysis on both the EEG sensor and source data. Since I'm interested in interhemispheric connectivity, my two scouts are on homologous regions of the two hemispheres. I want to see if the direction of causation is from left to right or from right to left.
I've understood how to go about it, in case of the source data. But I can't interpret the results of GC analysis on the sensor data.
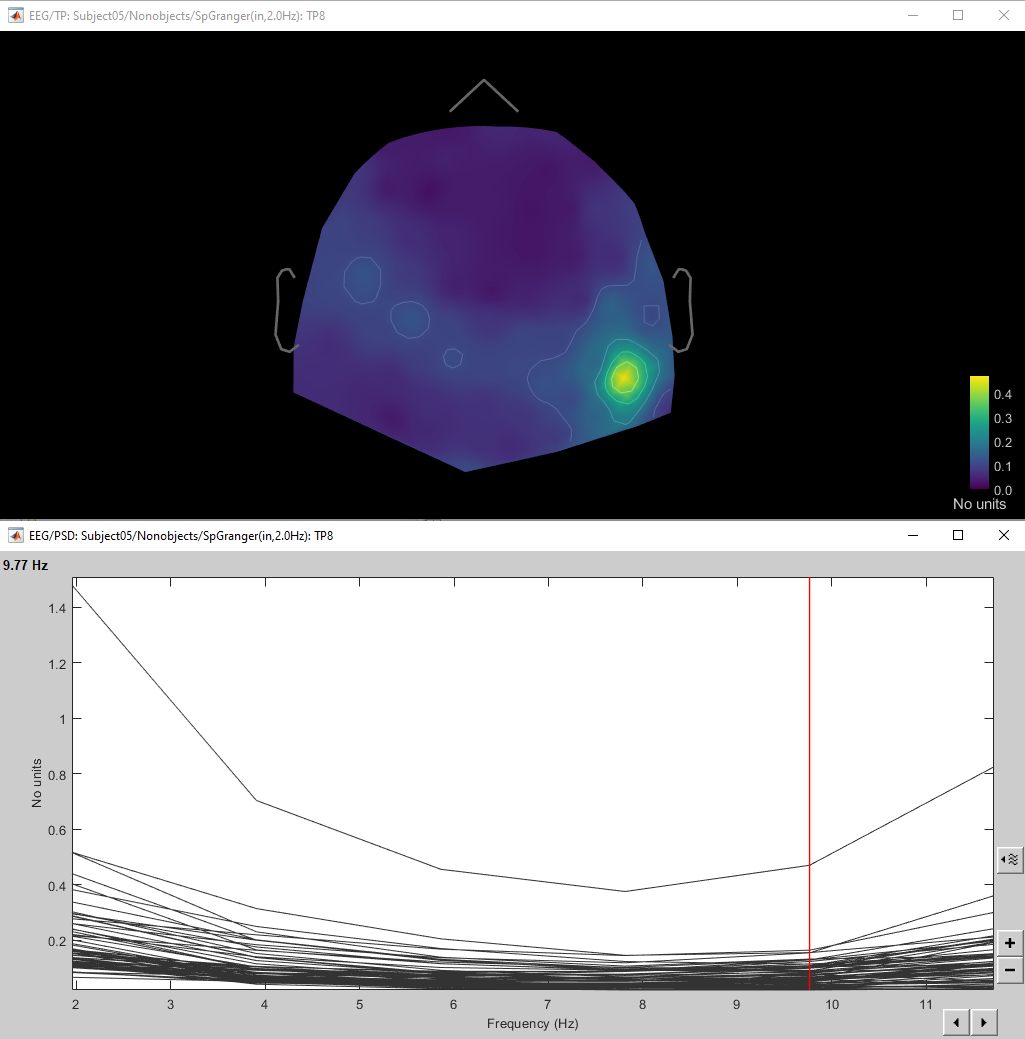
I used all the trials' time series files of one condition of one subject, in process 1 and computed GC 1xN analysis, using TP8 as my electrode and -0.5 to +1s as my time window. So I got 2 files as results, for in and out. Both are power spectra graphs. I've put the picture above.
If I have to specify sensor-wise, I'm interested in interactions in these pairs of electrodes: TP7-TP8, TP7-P8, P7-TP8, P7-P8. Now, I can export the file to MATLAB and then extract the values corresponding to these pairs which fall in my frequency of interest. That way, I'm getting one value for each pair. Previously, for the coherence analysis, I had extracted my required values this way and plotted them against time. But for Granger causality, what do I make of these values? How to interpret these, so that I can perform group analysis and statistically determine the causality if it exists?
Also, leaving the value extraction aside, how do I otherwise interpret the results that Brainstorm generated?
In this case F4 to F3 has bigger value than F3 - F4, it means that is more likely that data flows from F4 to F3, however, not every bigger value will be meaningful, there is no standard cut-off value, you can find out more in papers, some papers use 7 as a meaninful GC value.
Is you visualize data as connectivity Graph in BS, interpretation is even easier:
blue causes red
Previously, for the coherence analysis, I had extracted my required values this way and plotted them against time.
In a typical coherence analysis, there is no time either, you get one value for each frequency band.
Note that you get a spectrum because you used the spectral version of the GC metric, you could also use the broadband version.
But for Granger causality, what do I make of these values? How to interpret these, so that I can perform group analysis and statistically determine the causality if it exists? Also, leaving the value extraction aside, how do I otherwise interpret the results that Brainstorm generated?
Interpreting GC values is complicated: it is sensitive to noise and to the amount of data you feed the estimator, and there is no standard value that you can use as a threshold for "meaningfulness". If you want to know what is significant in your interactions, you need to compute the same measure on each subject, for at least two experimental conditions (you need a contrast vs. a reference measure), and then use a non-parametric test to identify what significantly different from your reference condition across all the subjects. https://neuroimage.usc.edu/brainstorm/Tutorials/Statistics#Nonparametric_permutation_tests
I'm still wondering how to interpret spectral Granger Causality (GC) after reading up on the tutorials and some threads.
If I understand correctly from this current thread, as well as this one: Frequency bands for Granger Causality (Spectral), that the resulting values from GC computation are unit-less, there is no threshold to these values, non-parametric permutation testing is required for thresholding the GC values, and perhaps because there are no units or thresholds to the resulting GC values from computation, GC results are hard to interpret. That is, it is hard to tell what is significant/meaningful.
That said, this thread hasn't been updated in a while, and I'm still somewhat confused on how I would practically threshold GC output to find significant/meaningful results.
Are there any new tools in Brainstorm that might make interpreting GC output more manageable? Is there any other guidance that you would provide for interpreting GC? I would like to use spectral GC.
Hello Adam,
The Connectivity tutorial has been expanded significantly recently.
For inference statistics on connectivity levels, we recommend you follow non-parametric approaches as described in this Statistics tutorial section.
Thank you for your response and guiding me to these tutorials.
I read in the advanced tutorial the following excerpt:
Pre-processing: The influence of pre-processing steps such as filtering and smoothing on GC estimates is a crucial issue. Studies have generally suggested to limit filtering only for artifact removal or to improve the stationarity of the data, but cautioned against band-pass filtering to isolate causal influence within a specific frequency band (Bressler and Seth, 2011).
Please forgive me for my naivety in the following remaining questions:
If I were to implement a 0.5-50 Hz bandpass filter on my raw data during preprocessing, would this filter invalidate/negatively impact Granger computation/interpretations that I make on it? If that answer depends on the frequency band(s) I'm interested in, those are beta & gamma. Seth (2010) J. Neurosci. Methods states that there were deviations in Granger results when a 1-100 Hz bandpass filter was applied, but I'm unsure how those results would apply to my filter. Further, Florin et al., Neuroimage didn't apply a bandpass filter that I can tell, so I'm left wondering how this bandpass filter may affect the data if I decide to use Granger.
Additionally, what is the range of output for Granger? I don't really see it listed anywhere. I was wondering whether it was on a 0-1 scale or 0 - infinity. I've also seen mentions of F tests between two time series.
Thank you again for your guidance. I'm trying to piece all this information together. I appreciate your help!