I'm analyzing sleep hd-EEG data using source PSD, comparing a specific sleep event vs baseline sleep with multiple subjects. After cleaning, marking bad channels and epoching, I use sLORETA (minimum norm, constraint, diag. noise covariance) and Welchs method to calculate the PSD. The result shows the highest power mostly at the lower part of the cortex (true also for different frequency bands).
Is this actually a problem for the group statistics or only for the interpretation of single epochs. My assumption was it’s not a problem for group statistics, but it’s not completely clear after reading forum and docs:
The problem seems to be similar to this one here:
from the forum-post above:
This is mostly a matter of colormap setting. In all cases, these maps should be normalized, you shouldn't try to interpret these maps directly. After computing group-level statistics with many subjects, the results obtained with the two forward models might not be very important.
And from the docs:
sLORETA maps are spatially smoother but with no direct statistical interpretation without further inference testing."
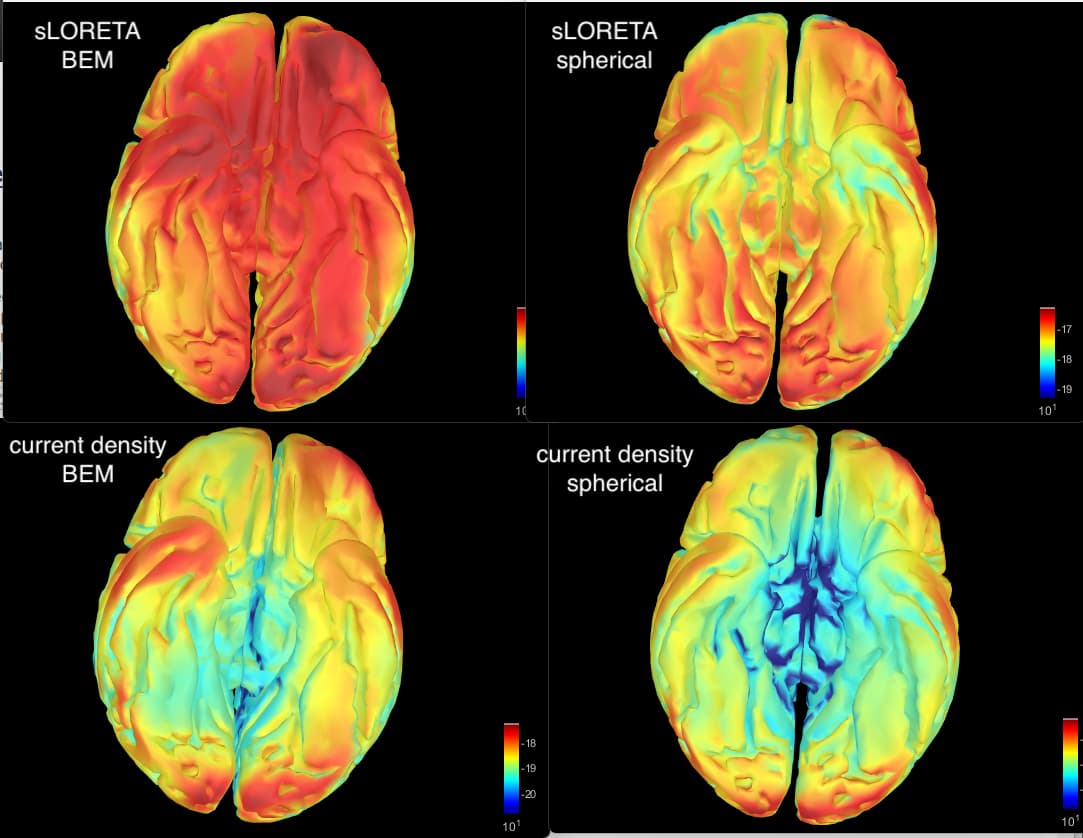
Further I use individual BEM head models for each subject (children). I also compared the result to a spherical model and to "current density map", which gives different results. But when calculating the relative power the current density and sLORETA looks the same (how to interpret?)
I am not sure what you mean by whether it is a problem for group statistics.
Nevertheless, we recommend that you standardize the power spectral density (PSD) values with respect to the total power of the signal to avoid artifactual power changes related to depth or source orientation. After computing source PSDs, please use the Relative Power process option, as explained in the following paper/pipeline: Brainstorm Pipeline Analysis of Resting-State Data From the Open MEG Archive - PMC
Thank you Sylvain for your reply and the explanation, I'll try that.
Just to understand, from the images above you don't think there is a specific problem with sLORETA?
I am not sure what you mean by whether it is a problem for group statistics.
That was my interpretation of the post from Francois, where he wrote that the differences in forward models might not be important after group statistics.
After computing group-level statistics with many subjects, the results obtained with the two forward models might not be very important.