I’m trying to obtain some information about the parameters related to the spatial smoothing function in BS,
I haven’t find any documentation, but maybe some of you have already use it and can give some advice,
You can define a Gaussian curve by its Full Width at Half Maximum (FWHM):
The last parameter defines how we apply the Gaussian smoothing kernel to the surface. This kernel size is defined in millimeters.
At a given vertex, we replace the value with a weighted average of the neighboring values. The weight is defined by the distance between the vertex and its neighbor.
This distance between two vertices can be estimated in different ways:
using the Euclidean distance between the two points (distance in the volume) => it smooths the activity between two vertices that are not connected (for instance, the two sides of a sulcus).
trying to recalculate the distance following the surface, following the edges that connect the points (distance on the surface) => The path that is used in my implementation is not the shortest path, and it doesn't work so well in regions where the topology is a bit complicated.
If found out that the average of the two methods was giving robust and acceptable results.
I have another question regarding the smoothing procedure,
I’m not sure if I should apply this procedure before or after I have conducted my interpolation procedure for group studies,
A priori, I would think that I have to smooth my individual data and then apply the interpolation, but I’m not sure about that,
Could you give me a hint?,
I’m sorry I don’t have good guidelines to give on how to proceed for the smoothing+projection.
There are many options that would give different results:
Absolute value > Smoothing > Projection
Absolute value > Projection > Smoothing
Smoothing > Absolute value > Projection
Projection > Absolute value > Smoothing
Smoothing > Projection (option that keeps the signals oscillating around zero)
Projection > Smoothing (option that keeps the signals oscillating around zero)
The approach you suggest can be either #1, #3 or #5.
Note that if you don’t apply an absolute value before the spatial smoothing, the positive and negative peaks that are close to each other in the minimum norm maps would tend to cancel each other, which is most likely not the expected behavior. This would go in favor of solutions #1, #2 or #4.
Solution #4 is interesting for optimization questions: it produces less copies of the full source matrices, as the projected imaging kernels are still stored in a compact form kernel+recordings.
In the current interface, you can achieve #1 easily by running successively “Spatial smoothing” (absolute values) and “Project sources” (absolute values).
I have not performed any test to compare those different options, I don’t know what we should recommend.
Maybe you can try on a few files to see the differences between #1, #2 and #4, before you process all your study.
What is generally accepted is that the individual data are smoothed (with the caveats concerning signed values as mentioned by Francois) before being projected on the template anatomy for group analysis. This is a practical manner to mitigate inter-individual anatomical variations.
All this is very helpful,
As a rule I always pick the absolute values of my sources. Not sure if is good, but this allow me to simplify my choices,
So, as for both the smoothing and the projection functions I always choose to calculate with absolute values,
This leave me only with two options, either I do smoothing > projection or projection > smoothing,
I have performed the first one, since it seemed to me respected more the individual anatomies,
I will peformed the second option and I will let you know,
Regarding the option #4 you mention Francois, when I do the projection I do not create a link (in the form kernel+recordings), not sure if is a bug, but for me I create a full new file (at least now when I’m testing, with absolute values),
Taking the absolute values of the source time series is the best choice to assess effects in magnitudes of ‘activation’ regardless of the phase of the signal. If later down the road you need to look into time-frequency decompositions or anything oscillatory, you’ll need to look at source maps that are not rectified.
Regarding the option #4 you mention Francois, when I do the projection I do not create a link (in the form kernel+recordings), not sure if is a bug, but for me I create a full new file (at least now when I'm testing, with absolute values)
This is normal when using absolute values. We can keep the imaging kernel form only when all the operations applied to the file are linear.
The absolute value is a non-linear operation, it cannot be represented as a matrix, therefore the source maps are automatically converted to full maps [Nvertices x Ntime]
By the way,
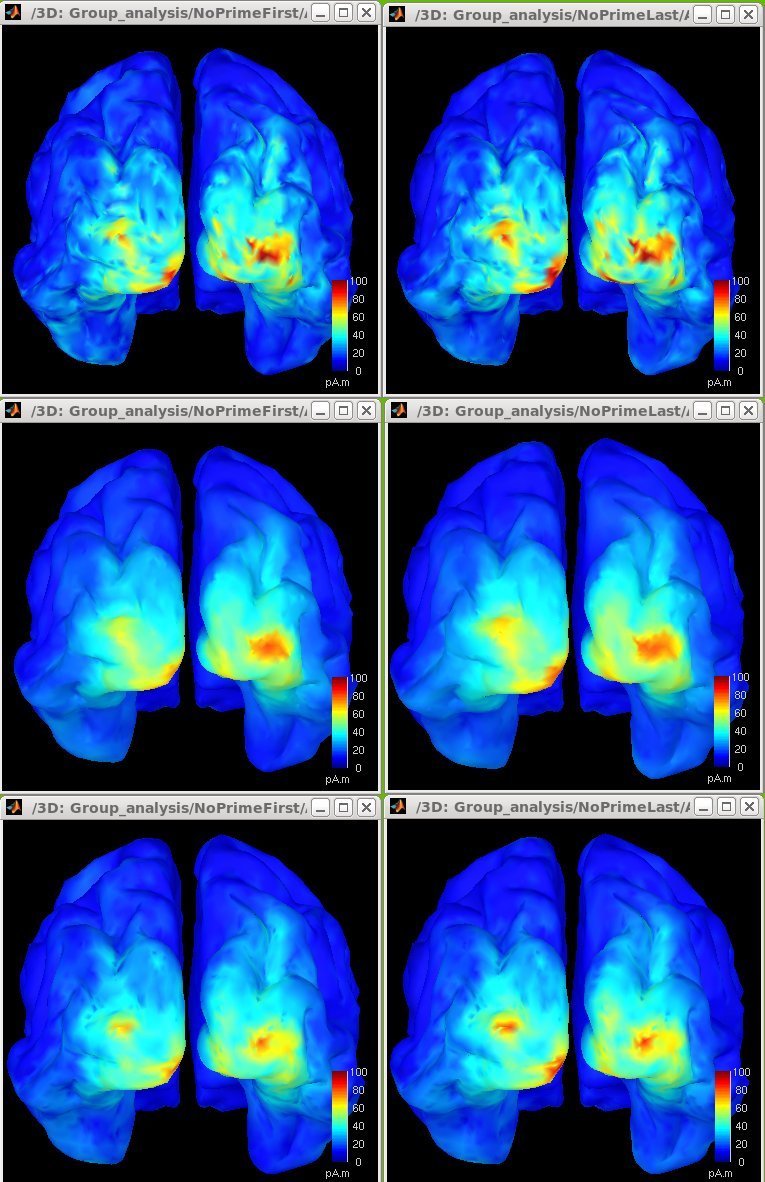
Here, attached is a comparison for the 3 ways I went with the smoothing/projections processes for 2 conditons of interest,
The 1st row are the sources merely re-projected on the default anatomy (i.e. constrained, then projected and averaged)
The 2nd row is sources > smoothing > projection, (for smoothing I use a value of 15, I try some few and this seem to be a good + average of the two methods)
The 3th row is sources > projection > smoothing,
I’d like to open this discussion back up, if I could. It sounds like the suggestion was:
[I]If you want to spatially smooth a source image, you should smooth at the individual anatomy level BEFORE projecting to a template brain.[/I]
However, this seems to be the [U]opposite[/U] of what is recommended for fMRI. The principles of fMRI are clearly different from MEG on many levels, but the recommendation for fMRI is to smooth AFTER normalization to a template brain when averaging subjects together. This link explains things well for fMRI (http://mindhive.mit.edu/node/112).
One reason I can think to do smoothing AFTER projection is so that the filter properties are consistent across subjects. For example, if a subject’s head is smaller than the template the warping will be expanding the original brain and will functionally expand any smoothing kernels that are applied before projection. Similarly, if a subject’s head is bigger than the template, the warping will shrink the brain and therefore shrink the smoothing kernel. This would mean the smoothness is brain-size dependent (e.g. smaller brain means smoother sources). I admit I have no idea how much this will really matter and I’m not even considering the nonlinearity of warping.
For fMRI, spatial smoothing increase SNR by attenuating voxel-independent noise AND by helping account for anatomy differences in a group. I’m not sure this first reason is valid for MEG where each source is not independent (i.e. recording noise will affect multiple sources at the same time due to the inverse kernel). It seems the second reason (i.e. group-anatomy) is the reason to do smoothing in MEG. To me, this means having the smoothing kernel be the same across all subjects in a group would make the most sense (e.g. [Project -> Smooth]). In fact, I’m not sure if smoothing MEG for individual subjects is valid (please correct me…I’d love to smooth my data).
I’d love to hear what other people think about this and please point out where I’m wrong.
In fMRI, normalization and realignment relies on the collected functional data. You often deal with spatially distorted volumetric data due to MR field inhomogeneity, signal loss in ventricles etc, and you may need non-linear transformations to achieve better registration. Registration will then work better on the original rather than smooth data because they have more information. In MEG, registration is performed independently of the collected functional data using head position coils. Smoothing or not smoothing the MEG data is irrelevant to the quality of registration.
Due to the folding of the cortical surface, neighboring voxels in MEG maps will have very different activation values and opposite sides of sulci will have opposite signs (in the case of orientation constrained reconstruction). Thus, when working on MEG orientation-constrained cortical maps, you should never smooth the signed data because neighboring strong positive and negative values will jointly become zero. You should only smooth absolute value maps or power maps.
MEG has a highly non-isotropic spatial resolution, with a resolution kernel often extending several sulci. Each subject has different anatomy and thus totally different non-isotropic spatial resolution. Aiming to achieve a uniform spatial resolution across subjects by smoothing is a lost cause.
I highly recommend you always spatially smooth MEG data for inter-subject studies, to compensate for the signal difference between the banks and fundi of sulci (tangential sources are strong, radial sources are nearly zero).
I also recommend you smooth your MEG data at the level of individual cortical anatomy, thus before inter-subject registration. Your smoothness will have physical meaning (FWHM on cortex) and will be consistent across subjects. On the other hand, when you register one cortex to another, a large cortical area can map to a small one and vice versa, gyri can map to sulci, and so on. Smoothing results will highly depend on registration in an unstructured and subject-specific way. For example, if radial sources expand, you will have a broader area with zero signal, which may not be recovered with spatial smoothing.
Thank you for your reply and detailed discussion on why smoothing is important. It sounds like we are basically in agreement about the purpose and importance of smoothing. However, I’m not really sure if there is a final solution to this question yet (or even if there is a general answer possible).
It sounds like you’re advocating for smoothing on the individual subject’s anatomy in all cases. This would prevent the smoothing kernel from being warped by the projection process and therefore the smoothing parameters will be directly related to spatial measurements on the individual subject. This is sensible. However, it seems like the opposite would also make sense: smoothing AFTER projection would ensure smoothing parameters are directly related to the spatial measurements of the [I]template[/I] brain.
I’m still left with the same conclusion I had before: if the point is to ensure the subjects lineup better, then smoothing at the template-level would make more sense so that the smoothing is consistent across subjects (as done in fMRI). However, if the point is to smooth the data to increase the SNR of the signal, then smoothing at the individual subject-level makes more sense. However, I’m still not sure smoothing to improve SNR is valid in MEG as it is in fMRI.