Hello Brainstorm community,
I have some questions based on the tutorial section Source estimation. The questions are regarding EEG and ERP data.
I have source maps that I need to average ACROSS different participants.
To do this, it looks like I need to standardize the source maps before averaging across participants.
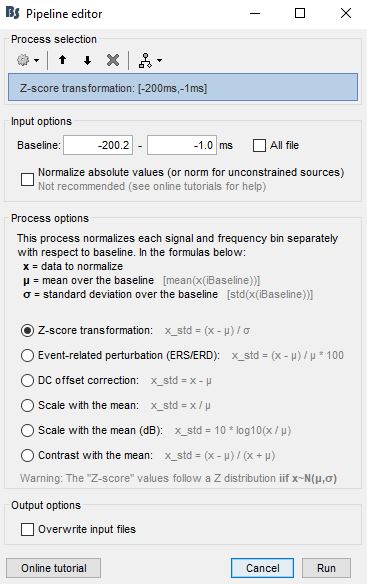
Out of the different ways to do this (shown below), what would be the pros and cons of each method? The tutorial seems to cover z-score transformation only.
As z-score transformation was the focus of the standardization I tried using this across my participants. However, I found the section below which seems to suggest that I should NOT average z-score maps at the subject level. Therefore does this mean that I should first average the non-standardized source maps across participants and THEN apply the z-score transformation on the grand-averaged source map? Or is this only applicable to those using current density maps? (I am currently using sLORETA).
Z-score
The same SNR issues arise while averaging Z-scores: the average of the Z-scores is lower than the Z-score of the average.
When computing averages at the subject level: Always avoid averaging Z-score maps.
Average the current density maps, then normalize.
Furthermore, if dealing with resting-state EEG and you want to z-score transform the data how would you do this as there is no reference segment? (because the data itself is resting-state).
We provided general recommendations for the pre-processing and analysis of ERP experiments (with EEG/MEG) in the Workflows tutorial. You may find relevant the sections related to source averages (subject and group) https://neuroimage.usc.edu/brainstorm/Tutorials/Workflows
Yes, it is necessary to standardize sources per participant, in order to compare (and average) them.
Different methods should leas similar results (although not equal). One of the advantages of z-score is that the outcome is given in standard-deviation units, thus it is simple to interpret them.
This is correct the subject average should be computed with non-standardized sources maps.
Compute sensor average of trials in a run
Compute sources for the sensor average in a run (this will be the source average per run)
If there are more than one runs, compute the weighted average across source averages per run
With sLORETA the current density maps are already normalized, but this is not based on the SNR.
Thus the subject averaged can be obtained as the weighted average across source averages per run
@Sylvain, would like add other aspects of using sLORETA?
z-scores are used to measure the changes (evoked by the condition) with respect to non-condition segment (baseline) in units that can be compared among subjects.
Can you elaborate on what is the goal of computing z-score on resting-state data?
To elaborate on what I am trying to achieve here;
I am comparing the sensor-level and source-level PSDs across the entire frequency spectrum as well as across frequency bands across three different groups.
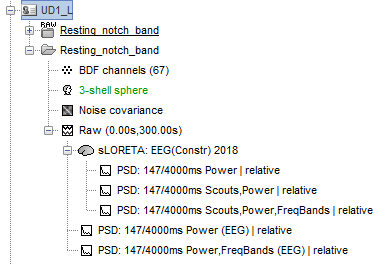
For source-level PSDs I am comparing all-scouts (i.e. whole brain) and specific scouts (left and right superior temporal gyri). The below data-tree for one participant explains what I mean.
Each person has an entire-frequency spectrum and FreqBands sensor level PSD and similarly for source level as well.
My question here is as follows and involves source-level PSDs;
If you have source maps that you need to average across participants, you need to average the non-standardized source maps and perform z-score transformation AFTER obtaining the grand-averaged source map.
However, as z-score is for evoked data (e.g. auditory evoked potential) applying z-score transformation to resting-state data doesn't make sense.
Therefore how would you perform some kind of standardization to individual source map PSDs before performing grand averaging? My take on this was to perform "Spectrum Normalisation > Relative power" to individual sensor as well as source maps before grand-averaging.
The normalization approach depends always of the analysis that will be performed.
Normalizing the sensor PSD with relative power, will make all the frequency components (or bands) sum up to one, thus the sensor PSD values are comparable across Subjects and Conditions, as it reduces the influences of the amplitude differences in the signals. However this type of normalization changes the distribution of power on the scalp within Subject, as now all the sensors will have have the same power (1).